Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Oracle Database@AWS goes GA: Exadata and Autonomous DB now live in the US | InfoWorld
Technology insight for the enterpriseOracle Database@AWS goes GA: Exadata and Autonomous DB now live in the US 9 Jul 2025, 5:32 am
Oracle and AWS have expanded their collaboration to make the Oracle Database@AWS service generally available in the US.
The Oracle Database@AWS service, previewed in September last year, is a continuation of Oracle’s strategy to partner with hyperscalers to offer its database services in the latter’s infrastructure.
In September 2023, Oracle started collocating its Oracle database hardware (including Oracle Exadata) and software in Microsoft Azure data centers, giving customers direct access to Oracle database services running on Oracle Cloud Infrastructure (OCI) via Azure.
Last year in June, Oracle signed a similar deal with Google to make its database services more widely available.
Oracle Database@AWS entered limited preview in December, and customers who signed up for early access were able to run and try out Oracle Exadata Database Service on OCI in AWS, starting with the US East region in Northern Virginia.
“We are now GA across two regions — AWS US East (N. Virginia) and US West (Oregon) regions with Oracle Exadata Database Service and Oracle Autonomous Database on dedicated infrastructure on OCI within AWS,” an Oracle spokesperson said.
The cloud region strategy
Explaining Oracle and AWS’ strategy to offer the limited preview in Northern Virginia first and later expand to Oregon with general availability, Shelly Kramer, founder and principal analyst at Kramer & Company, said that both regions serve the vast majority of AWS’ US customer base.
“North Virginia is AWS’s largest, oldest, most mature, and most widely used AWS region. Likewise, Oregon is considered the flagship for AWS’ western presence,” Kramer added.
Furthermore, Kramer noted that the choice of the two regions is a well-thought-out strategy.
“Oracle Database@AWS requires integration with Oracle Cloud Infrastructure (OCI) regions, and both North Virginia and Oregon are paired with OCI regions in Phoenix, Arizona, and Ashburn, Virginia. This enables seamless service provisioning and connectivity between AWS and OCI, which is crucial for customers,” Kramer said.
Starting in two key regions also enables the fine-tuning of performance optimization and the integration of customer feedback before rolling out to other areas, Kramer added.
The availability of the service across two regions in the US will allow more customers to adopt the service as more regions mean more capacity, said Tobi Bet, senior director analyst at Gartner.
Separately, Forrester VP and principal analyst Noel Yuhanna pointed out that the service being available in two regions provides the critical resiliency needed for enterprises to run mission-critical workloads reliably in the cloud.
The focus, according to Yuhanna, is on ensuring high availability, and since the regions are geographically isolated, an outage in one doesn’t necessarily impact the other.
Availability in 20 additional regions
In addition to the US regions, Oracle and AWS plan to expand the availability of Oracle Database@AWS to 20 regions over the next 12-18 months, said Kambiz Aghili, VP of Oracle Cloud Infrastructure.
These regions include Canada (Central), Frankfurt, Hyderabad, Ireland, London, Melbourne, Milan, Mumbai, Osaka, Paris, São Paulo, Seoul, Singapore, Spain, Stockholm, Sydney, Tokyo, US East (Ohio), US West (N. California), and Zurich.
These additional regions will make it easier for enterprises to comply with data sovereignty requirements while still taking advantage of the cloud, said David Menninger, director at ISG Software Research.
“Also, if an enterprise is seeking to adopt a multicloud strategy, the more regions available, the more options available to it to split or share workloads,” Menninger added.
Explaining further, Menninger said that additional regions are likely to benefit two types of enterprises — large multinationals that operate in multiple regions and relatively smaller, local enterprises that want to utilize local cloud services.
These additional regions, according to Bradley Shimmin, lead of the data and analytics practice at The Futurum Group, will help in the uptake of the service.
Enterprise decision makers these days favor optionality, particularly in managing data assets and any service offering a single provisioning, management, governance, and observability pane for that data across diverse deployment strata, just like Oracle Database@Azure, will ultimately win over siloed or complex multi-hybrid cloud capabilities, Shimmin explained.
The analyst was referring to Oracle Database@AWS’ capabilities such as simplified management, unified billing, and zero-ETL.
{kind=link}
Get started with Google Agent Development Kit 9 Jul 2025, 5:00 am
A common use case in generative AI is developing an agent, which is a system users interact with in plain language to accomplish a given task. Creating AI agents can require a lot of heavy lifting, even when you’re leveraging an existing commercial model.
Google recently released the Agent Development Kit, a library for Python and Java that handles many boilerplate aspects of creating AI agents. The Google Agent Development Kit supports developing agents for simple tasks or complex multi-step workflows. And while the toolkit works naturally with Google’s own AI models like Gemini, it’s not difficult to adapt it to most any AI model served through an API.
Setting up Google Agent Development Kit
The Agent Development Kit, or ADK for short, supports two languages, Python and Java. We’ll work with the Python version.
To get started with the kit, create a new virtual environment and install the ADK into it with pip install google-adk. Note that this installs a large number of dependencies—84, as of this writing—so be prepared to devote around 285 MB of space for the environment and its dependencies alone.
You’ll also want to create an .env file in the root of your project to hold the API keys for the AI services you’ll connect with. The ADK automatically detects .env files and uses their contents, so you don’t need to write any code to handle that.
Developing a basic AI agent
Let’s set up a basic agent that does nothing more than scour the Internet for answers to questions.
In your project directory, create a subdirectory named searchagent. Inside, we’ll place two files: __init__.py and agent.py.
Here’s the code for __init__.py
from . import agent
And here is agent.py:
from google.adk.agents import Agent
from google.adk.tools import google_search
root_agent = Agent(
name="search_assistant",
description="An agent that answers questions augmented with web searches.",
model="gemini-2.0-flash",
instruction="Answer questions provided by the user. Compare and contrast information gathered from Google with your own information. If you are given a statement that is not a question, reply, 'Please ask me a question.'",
tools=[google_search]
)
Whenever we want to create a distinct agent, we set up a subdirectory in our main project directory and give it a name (in this case, searchagent). This lets us have multiple agents in a single project, which can run on their own or interoperate.
The __init__.py file marks the directory as being an agent, by importing the actual agent code. The agent.py file sets up the agent itself, as described by the Agent object.
Each Agent uses a model API to interface with (here, it’s gemini-2.0-flash). Our initial commands to the agent, which prefix each input from the user, are defined in instructions. Note that these instructions can be far more detailed than what we’re providing here. The tools section provides additional tooling that can be used by the agent; google_search lets the agent use Google searches to augment its results.
To run this example locally using a web interface, open a command line, activate the venv, and use the command adk web. After a pause, you’ll get a prompt that the ADK’s web interface is running on port 8000.
Navigate to http://localhost:8000 in your browser, and you’ll see the default ADK web interface, with the simpleagent agent ready to run. If you have multiple agents configured for a given project, the dropdown at the top left of the page lets you choose between them.
To ensure the agent is running properly, type a question to be researched in the pane at the bottom of the web page and press Enter. The results should show up in a few seconds:
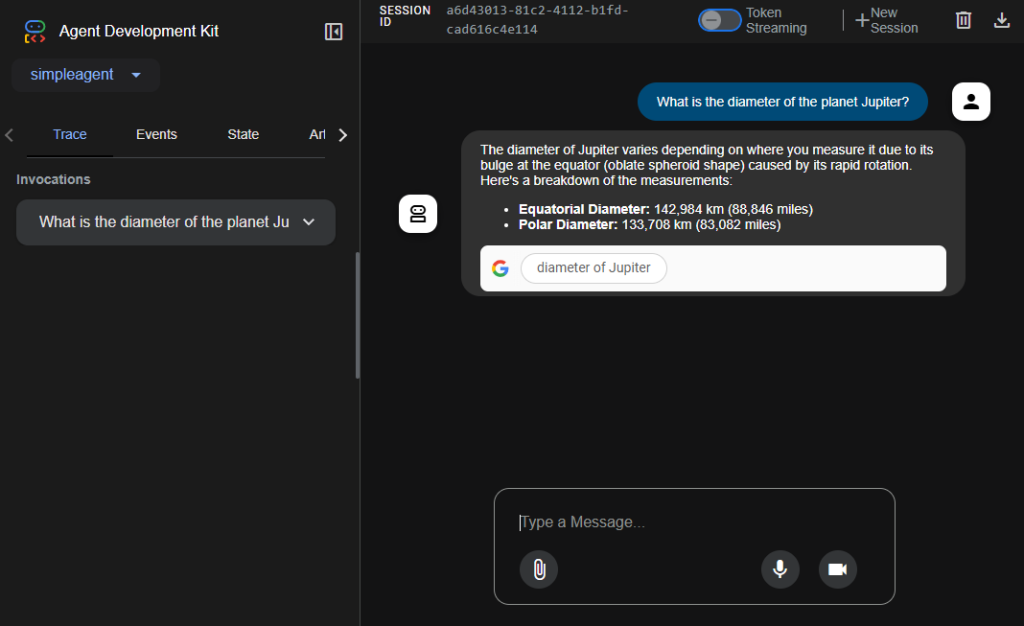
IDG
The left-hand side of the web UI provides debugging information for each conversation you have with the agent. If you click the “bot” icon to the left of the conversation, you’ll see the back-end details for that conversation, including metadata returned by the service about its activity. The details will vary across services:
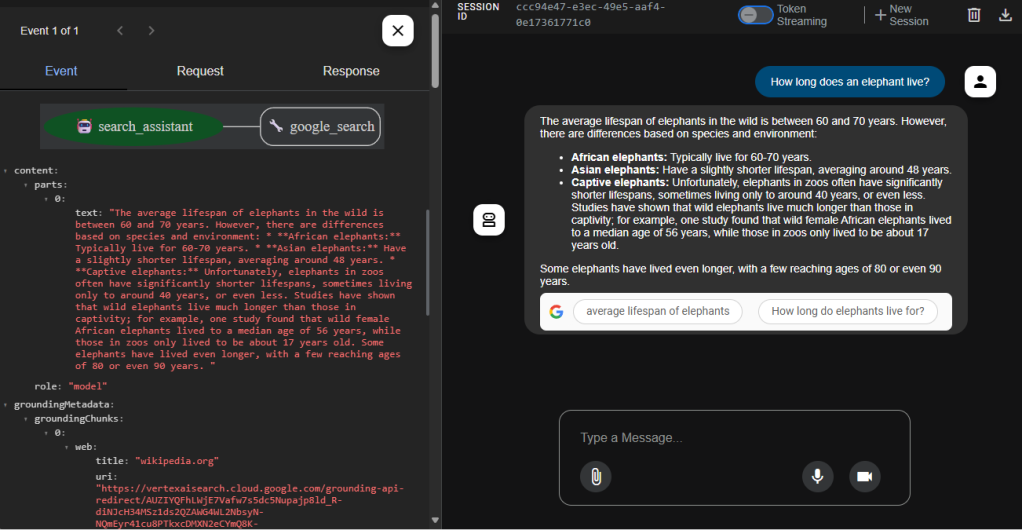
IDG
If you select the Token Streaming option at the top of the chat window, the results will be returned gradually, word-by-word, rather than all at once.
Developing a multi-agent architecture
One of ADK’s strengths is how it lets you create agent systems that involve more than one agent at a time. Interactions between agents can be composed using what are called workflow agents.
Workflow agents launch AI agent tasks, then handle how they execute in strongly predetermined ways. These aren’t AI agents themselves; they’re just programs written in Python or Java. But they can greatly expand on how agents operate.
Workflow agents come in several different varieties:
- Sequential agents: A sequential agent feeds user input to a given LLM or workflow, takes the results, and then feeds them to another LLM or workflow (with some additional prompting for how that agent should handle the input). This way, one agent can be used to transform or refine the output of another. An example of this would be an agent that generates a text, and another agent that rewrites it in a specific verbal style.
- Loop agents: A loop agent takes a given input, feeds it to an LLM or workflow, then re-runs the same process until some condition is met. This condition could be something entirely mechanical, like running the loop x times in a row. But it can also be about having another LLM agent check for some criteria; for instance, by asking, “Does this output satisfy these conditions?” An example would be one agent that generates a simplified text from a larger one, and another that determines whether the simplified text omits any crucial details; if it does omit details, then a new condensed text gets generated. This could continue indefinitely, or (more likely) for a fixed number of loops.
- Parallel agents: Parallel agents execute two or more agent jobs side by side, then yield the results only when all the jobs are complete. No state is shared between the jobs as they’re running; they all have to be supplied with the needed data upfront. An example of this would be an agent that uses three different search engines as part of the fact-checking process for a document. Each fact-checking pass is conducted side by side with a different search engine, and the results are then combined after all the searches finish.
It’s important to remember that these agents are really just Python or Java programs. Because of that, they’re limited by the behaviors of conventional programs. For instance, a parallel agent is limited by whatever it attempts to do in parallel. If you use the agent to run multiple jobs on a remote service that only accepts one job at a time from your API key, you won’t have a parallel agent anymore.
Tools in the Agent Development Kit
Agents in the ADK can also rely on Tools to augment the way they work. A “Tool” in this context is just a piece of Python or Java code that interfaces with non-LLM components, such as fetching something from a URL endpoint, retrieving something from a database, or doing some other action that doesn’t require an LLM—although it may use data generated by an LLM to get things done.
ADK Tools come in three basic categories:
- Function tools wrap existing functions in the language you’ve written. They return JSON, so all data types used for return values must be JSON-serializable by default. Functions can be set to run without blocking other behaviors, and can also function as agents—in effect, calling an agent as if it were a tool and using its response as the tool’s response.
- Built-in tools provide common stock functions, like Google Search, so you don’t have to implement them from scratch. You can also run arbitrary code or run Google Vertex AI Search through built-ins.
- Third-party tools let other developers provide tools to be used in your own workflows, like LangChain.
Any existing business logic you want to connect to an ADK-powered agent is best done with a Tool of some kind, rather than by copying the logic into the agent code. You can write the logic directly into the agent if you simply want to experiment, but anything production-worthy should be done through a Tool interface.
Example projects in the Agent Development Kit
One good way to start working with the ADK is to look at the existing roster of example projects and repurpose one for your own needs. They cover a broad variety of use cases and behaviors, so a pattern you want to replicate is likely already covered there:
- LLM auditor: An automated fact-checking system with two agents: one to verify a claim, and another to produce a rewritten version of the original claim that conforms to the verified facts. This example uses a sequential agent architecture, so your own sequential agent system could be patterned after this.
- Customer service: A customer-service agent that connects with different back-end services to perform various customer-service tasks. Many different tools are mocked up through this example (e.g., making video calls or speaking to services like Salesforce), so this example could be hitched to actual back-end services as needed.
- Image scoring agent: Generates images and validates the results based on criteria supplied to another agent that evaluates the generated images. This example uses a loop agent, so a project that requires continuously refining input could use this as a basis.
{kind=link}
The ultimate software engineering abstraction 9 Jul 2025, 5:00 am
Really big changes don’t happen in the programming world very often. I’ve been lucky to be around long enough to see a couple of them. And we are all lucky enough to be seeing one today.
I remember well the heady days in the mid-1990s when rapid application development was changing the way software was built. Being able to produce a Windows application with a few drag-n-drops and a few lines of code was a huge leap past the original way of directly accessing the Win32 API to construct a simple window.
With the release of tools like Visual Basic and Delphi, we finally saw the fruit of object-oriented programming, which allowed us to build applications for Windows much more efficiently. The new IDEs were powerful; I remember the advent of IntelliSense and how cool that was. Clicking on a method declaration and being taken to the implementation was mind-bending.
But that is all old hat now, eh?
Code what I say
A while back, I wrote about how AI is changing the coding landscape. Then, a couple of months later, I wrote about my experience building a website by “vibe coding” — meaning, using AI to write code interactively, in the flow, based on your intent.
In terms of “AI years,” that was a century ago. We used to talk about “Internet time” and how things were all sped up. But AI? I think things are moving exponentially faster. AI coding is in a kind of virtuous feeding frenzy, where AI is rapidly making AI better. Things are moving so quickly that the model I used back in March is, well, child’s play compared to what the models can do today.
Of course, “vibe coding” was an informal name. Properly speaking, we are doing “agentic coding,” where a coding agent does all the work, and you just tell it what to do.
We have IDEs designed specifically for agentic coding. But even the IDE is starting to become less relevant, as OpenAI’s Codex is more like a new kind of command line. You type what you want in plain English, then you review the code changes, and Codex makes a pull request for you. It makes IntelliSense look like some quaint technology of the distant past. It doesn’t take much imagination to see that this is a huge, order-of-magnitude change in productivity.
It occurred to me that agentic coding is just a natural step in the continuous application of abstractions. First we had ones and zeros. Those were replaced by assembly language. Then assembly was replaced by higher-order languages. We’ve built things like the JVM and .NET to abstract away the hardware. And of course, the browser pretty much abstracted everything.
But now? We have created an abstraction layer that can understand people talking and writing. Agentic coding is the compiling of a spoken language into a high-level programming language, be it JavaScript or Ruby or Rust or whatever.
At some point, it won’t matter what the underlying language is. Shoot, let the agent decide what the best tool for the job is. It’s conceivable that agentic coding will advance to the point where the code itself just doesn’t matter.
A higher level
And the really scary part? It’s just getting started. The quality and capabilities of agentic coding are in the infancy stage and only going to get better and better and better. A year ago, we didn’t even think about this kind of thing. Today? If you aren’t on board or getting on board, you will fall behind even faster than if you didn’t pay attention when web development took off.
Or maybe not. Right now, success with agentic coding requires a certain level of skill. If the agent generates bad code or follows poor practices, it takes a certain amount of expertise to recognize that. It is not far-fetched, however, to imagine the agent becoming so good at coding that expertise will no longer be required.
When high-level languages first required compilers, many thought no machine could write better assembly language than humans. But that concern was put to rest long ago. It’s not unreasonable to think that AI will eventually “compile” your spoken words better than you ever could. Someday, we won’t even look at the code that our AI agent produces. We’ll take it for granted, just as we do the assembly code in our software today.
So maybe the notion of needing special skills to develop software will go away all together. Perhaps coding agents will become so good that anyone with an idea can build an app or a website, all by just talking about it, describing what they want, seeing the results, and iterating. The day is coming when anyone with an idea and a little time can build anything.
And if that isn’t a huge leap in productivity that will change the world, I don’t know what is.
{kind=link}
Artificial intelligence is a commodity, but understanding is a superpower 9 Jul 2025, 5:00 am
The debate about intelligence versus wisdom is as old as history, but artificial intelligence has transformed it into an intensely practical question. The cheaper professional knowledge becomes, the more precious it is to know how to wield it. It’s becoming ever clearer that the most valuable thing is not just the power to do things but wielding it effectively. Formulating and comprehending aims in the context of complex systems and uniting the burgeoning sprawl of content with clarity of strategic vision: These are stars of the new game.
This is nowhere truer than in software development, where content is executable. Here we have a bizarre paradox where it’s a known fact that more lines of code means more surface of maintenance, where established practice shows that more output != better outcomes. And yet the current fad is that people who understand software—software developers—will soon be replaced by AI.
Honestly, I think the inverse might be closer to the truth. The heart of a developer’s skill set is the ability to move between ideas, goals, and implementation in software. As it turns out, this corner of the universe is currently growing by orders of magnitude. While anyone can now use human language to generate working code from AI, each time they do, developers have a bit more territory to roam.
Maybe the generated code is of high quality, meets the requirements, and integrates with the overall project intent and infrastructure. Maybe it’s easy to understand and maintain; maybe it isn’t. Code that is well-thought-out and delivered implies comprehension of both the goals and the underlying system. And you know what you call a person who does that? A software developer.
AI can’t deliver that sort of code because AI doesn’t understand anything. To take in and absorb the importance of things is a purely human function. It is also hard work. It is becoming ever more rare, at just the moment when it is becoming even more necessary.
Intention as the middle ground of enterprise innovation
The middle ground of enterprise innovation is where strategic goals are connected to business and development activity. This middle ground of bridging intention is where purpose meets technique. It is something AI cannot do without human guidance. It can only assist.
As a developer and a human being, you want to push yourself as much as possible to incorporate the intention of things into your practice. By insisting on understanding a project’s intention and uniting it with your own understanding of the particulars of implementation, you become far more valuable. AI then makes it easier to magnify your intentions into automated activity.
We can speculate that AI will get better at this middle ground in the future, but it will never actually have intention. It will only ever move under human direction. Resist becoming just a connector or interpreter of intention to implementation. Keep on working to develop and contribute your own unique understanding. Implementation can be automated, but the unique qualities of understanding cannot.
Why LLMs will not replace higher-level languages
If you follow the hype cycle, it might seem that AI’s ability to mass produce code to meet requirements makes understanding the intention of that code less important. I’d say it makes it less necessary up front. There may even come a time when AI’s natural language interface is something like what fourth-generation languages are today. I can see a possible future where languages like JavaScript and Python are a layer below the AI interface, akin to how C is today. But if that is the analogy we’re using, then it seems clear we will always need people who deeply understand that layer, just as today we still need people who understand C, assembly machine code, and chip wafers.
But I don’t really see large language models wholesale replacing higher-level language programming anytime soon, if ever. The current generation puts immense pressure on the humans involved to ensure minimal change and conciseness. These things, as we well know from experience, are utterly essential. Getting the job done versus getting it done gracefully is not a trivial distinction when it comes to programming.
You can abstract the way a loop is implemented. You might be able to use the LLM instead of a for loop or a forEach function. But somewhere in there, it’s still implemented as a loop or function. Someone still needs to understand the concept of iteration as it relates to data and the system where it operates.
Finger pointing at the moon
It is notable that the Gartner Hype Cycle in June 2024 had generative AI on the downslope, rushing quickly toward the slough of disillusionment. When something has so much excitement and potential around it, it’s tough to stand aside and see it clearly, but that’s exactly what we as developers need to do. We have the perspective to really understand what AI can and can’t do and use it in the best ways. The more we do that, the better the results will be for all of us.
{kind=link}
The fact is that AI is trained on the average output of humanity, so you’re going to get average results. Extraordinary genius and everyday excellence in human achievement result from tying the intangibles, intention, and the spirit of creativity into the minutiae of medium and technique. AI can only give a sampled approximation of things, not the living core. That core is the source of genius.
In Zen terms, and the philosophy of Bruce Lee, AI is all finger pointing at the moon, but no moon.
Intelligence versus wisdom
I learned how to play Dungeons & Dragons years ago, and the distinction between the intelligence and wisdom attributes was explained to me as “knowing it’s raining” versus “knowing to come in out of the rain.” Another way to render this is knowing how to do versus what should be done.
For me, intelligence moves toward reduction, whereas wisdom moves toward integration. Intelligence sees the parts and wisdom sees the whole. We need both, obviously, and embracing both is what I’m advocating for here. The fact that intelligence can be artificially produced calls for exercising both intelligence and wisdom more effectively, but especially wisdom. We will need all the wisdom we can get to manage the expanding volume of content created without understanding.
As a developer, your unique perspective and how you bring varied elements together are irreplaceable. At whatever level and in whatever context you find it, understanding is the most precious thing. Understand deeply, and everything else will flow from that.
{kind=link}
Clarifai AI Runners connect local models to cloud 8 Jul 2025, 8:12 pm
AI platform company Clarifai has launched AI Runners, an offering designed to give developers and MLops engineers flexible options for deploying and managing AI models.
Unveiled July 8, AI Runners let users connect models running on local machines or private servers directly to Clarifai’s AI platform via a publicly accessible API, the company said. Noting the rise of agentic AI, Clarifai said AI Runners provide a cost-effective, secure solution for managing the escalating demands of AI workloads, describing them as “essentially ngrok for AI models, letting you build on your current setup and keep your models exactly where you want them, yet still get all the power and robustness of Clarifai’s API for your biggest agentic AI ideas.”
Clarifai said its platform allows developers to run their models or MCP (Model Context Protocol) tools on a local development machine, an on-premises server, or a private cloud cluster. Connection to the Clarifai API then can be done without complex networking, the company said. This means users can keep sensitive data and custom models within their own environment and leverage existing compute infrastructure without vendor lock-in. AI Runners enable serving of custom models through the Clarifai’s publicly accessible API, enabling integration into any application. Users can build multi-step AI workflows by chaining local models with thousands of models available on the Clarifai platform.
AI Runners thereby simplify the development workflow, making AI development accessible and cost-effectve by starting locally, then scaling to production in Kubernetes-based clusters on the Clarifai platform, the company said.
{kind=link}
ECMAScript 2025 JavaScript standard approved 8 Jul 2025, 4:10 pm
ECMAScript 2025, the latest version of the ECMA International standard for JavaScript, has been officially approved. The specification standardizes new JavaScript capabilities including JSON modules, import attributes, new Set methods, sync iterator helpers, and regular expression modifiers.
The ECMAScript 2025 specification was finalized by ECMA International on June 25. All told, nine finished proposals on the ECMAScript development committee’s GitHub page were approved. Another proposal slated for 2025, for time duration formatting objects, appears on a different page. Development of ECMAScript is under the jurisdiction of the ECMA International Technical Committee 39 (TC39).
Note that many new JavaScript features appear in browsers even before new ECMAScript standards are approved. “One thing to note is that the vast majority of web developers are more attentive when these various features become available in their favorite browser or runtime as opposed to it being added to the JS spec, which happens afterwards,” said Ujjwal Sharma, co-chair of TC39 and co-editor of ECMA-402, the ECMAScript internationalization API specification.
For JSON modules, the proposal calls for importing JSON files as modules. This plan builds on the import attributes proposal to add the ability to import a JSON module in a common way across JavaScript environments.
For regular expressions, the regular expression escaping proposal is intended to address a situation in which developers want to build a regular expression out of a string without treating special characters from the string as special regular expression tokens, while the regular expression pattern modifiers provides the capability to control a subset of regular expression flags with a subexpression. Modifiers are especially helpful when regular expressions are defined in a context where executable code cannot be evaluated, such as a JSON configuration file of a Textmate language grammar file, the proposal states.
Also in the “regex” vein, the duplicate named capturing groups proposal allows regular expression capturing group names to be repeated. Prior to this proposal, named capturing groups in JavaScript were required to be unique.
The sync iterator helpers proposal introduces several interfaces to help with general usage and consumption of iterators in ECMAScript. Iterators are a way to represent large or possibly infinitely enumerable data sets.
Other finalized specifications for ECMAScript 2025 include:
- DurationFormat objects, an ECMAScript API specification proposal. Motivating this proposal is that users need all types of time duration formatting depending on the requirements of their application.
- Specifications and a reference implementation for Promise.try, which allows optimistically synchronous but safe execution of a function, and being able to work with a Promise afterward. It mirrors the async function.
- Float 16 on TypedArrays, DataView, and Math.f16round, which adds float16 (aka half-precision or binary16) TypedArrays to JavaScript. This plan would add a new kind of TypedArray, Float16Array, to complement the existing Float32Array and Float64Array. It also would add two new methods on DataView for reading and setting float16 values, as getFloat16 and setFloat16, to complement the existing similar methods for working with full and double precision floats. Also featured is Math.f16round, to complement the existing Math.fround. Among the benefits of this proposal is its usefulness for GPU operations.
- Import attributes, which provide syntax to import ECMAScript modules with assertions. An inline syntax for module import statements would pass on more information alongside the module specifier. The initial application for these attributes will be to support additional types of modules across JavaScript environments, beginning with JSON modules.
- Set methods for JavaScript, which add methods like union and intersection to JavaScript’s built-in Set class. Methods to be added include Set.prototype.intersection(other), Set.prototype.union(other), Set.prototype.difference(other), Set.prototype.symmetricDifference(other), Set.prototype.isSubsetOf(other), Set.prototype.isSupersetOf(other), Set.prototype.isDisjointFrom(other). These methods would require their arguments to be a Set, or at least something that looks like a Set in terms of having a numeric size property as well as keys and has methods.
The development of the ECMAScript language specification started in November 1996, based on several originating technologies including JavaScript and Microsoft’s JScript. Last year’s ECMAScript 2024 specification included features such as resizing and transferring ArrayBuffers and SharedArrayBuffers and more advanced regular expression features for working with sets of strings.
{kind=link}
InfoWorld Technology of the Year Awards 2025 nominations now open 8 Jul 2025, 12:29 pm
Welcome to the 25th annual InfoWorld Technology of the Year Awards.
The InfoWorld Technology of the Year Awards recognize the best and most innovative products in software development, cloud computing, data analytics, and artificial intelligence and machine learning (AI/ML).
Since 2001, the InfoWorld Technology of the Year Awards have celebrated the most groundbreaking products in information technology—the products that change how companies operate and how people work. Winners will be selected in 30 product categories by a panel of judges based on technology impact, business impact, and innovation.
Enter here to win.
Nominations cost:
- $99 through Friday, July 18, 2025
- $149 through Friday, August 2, 2025
- $199 through Friday, August 15, 2025
Products must be available for sale and supported in the US to be eligible for consideration.
If you have any questions about the awards program, please contact InfoWorldAwards@foundryco.com.
Products in the following categories are eligible to win:
- AI and machine learning: Governance
- AI and machine learning: MLOps
- AI and machine learning: Models
- AI and machine learning: Platforms
- AI and machine learning: Security
- AI and machine learning: Tools
- API management
- API security
- Application management
- Application networking
- Application security
- Business intelligence and analytics
- Cloud backup and disaster recovery
- Cloud compliance and governance
- Cloud cost management
- Cloud security
- Data management: Databases
- Data management: Governance
- Data management: Integration
- Data management: Pipelines
- Data management: Streaming
- DevOps: Analytics
- DevOps: CI/CD
- DevOps: Code quality
- DevOps: Observability
- DevOps: Productivity
- Software development: Platforms
- Software development: Security
- Software development: Testing
- Software development: Tools
Read about the winners of InfoWorld’s 2024 Technology of the Year Awards here.
{kind=link}
Metadata: Your ticket to the AI party 8 Jul 2025, 9:14 am
Agentic AI is fundamentally reshaping how software interacts with the world. New frameworks for agent-to-agent collaboration and multi-agent control planes promise a future where software acts with more autonomy and shared context than ever before. Yet amid all this excitement, one quietly persistent idea holds everything together: metadata.
Known in data management circles for decades, metadata is the foundational layer determining whether your AI goals scale with confidence—across petabytes of data and hundreds of initiatives—or stutter into chaos and unreliability.
Many teams pour energy into large models and orchestration logic but overlook a simple truth: Without a modern metadata strategy, even the most advanced AI systems struggle to find the right data, interpret it correctly, and use it responsibly.
Metadata is the key that lets every asset, model, and agent know where it is, how it’s found, and what rules apply. In this new era of autonomous workflows and dynamic reasoning, it’s no exaggeration to call metadata your ticket to the AI party.
Discover, understand, trust, and use
Modern AI needs more than raw data. It needs context that evolves as new sources appear and applications multiply. This context is reflected in four practical capabilities essential for any robust metadata infrastructure: discover, understand, trust, and use.
Discover means navigating billions of objects without tedious manual work. A modern metadata system automates metadata harvesting across diverse data stores, lakes, and third-party databases. Smart cataloging and search capabilities let anyone ask, “Where is my customer data?” and get precise, policy-safe answers instantly.
Understand turns raw schema into human-friendly context. An effective metadata strategy enriches cataloged assets with business glossaries and collaborative documentation. Generative AI can help auto-describe technical fields and align them with familiar business language. These context shells ensure people and agents can reason clearly about what the data represents.
Trust flows from continuous quality and visible lineage. Metadata infrastructure should profile and score data health, flag issues automatically, and generate quality rules that scale as your footprint grows. Lineage graphs reveal how raw feeds turn into curated data products. This is governance at work behind the scenes, ensuring consistency and reliability without the overhead.
Use is where value becomes real. When discovery, understanding, and trust are robust, reliable data products become achievable. Teams can design these products with clear service level expectations, just like application contracts. They support dashboards for analysts and APIs for agents, all backed by real-time governance that follows the data.
From classic management to agentic reality
Metadata’s role has evolved dramatically. It used to index static tables for scheduled reports. Today’s agentic AI demands an always-on metadata layer that stays synchronized across petabytes and thousands of ever-changing sources.
Take a simple natural language query. A business user might ask, “Show me my top selling products this quarter.” A well-architected metadata layer resolves vague terms, maps them to trusted data sources, applies governance rules, and returns reliable, explainable answers. This happens instantly whether the request comes from a human analyst or an agent managing supply chain forecasts in real time.
Dataplex Universal Catalog: A unified approach to metadata management
At Google Cloud, we built Dataplex Universal Catalog to turn this vision into everyday reality. Rather than cobbling together separate catalogs, policy engines, and quality checks, Dataplex Universal Catalog weaves discovery, governance, and intelligent metadata management into a single cloud-native fabric. It transforms fragmented data silos into a governed, context-rich foundation ready to power both humans and agents.
Dataplex Universal Catalog combines cataloging, quality, governance, and intelligence in a single managed fabric. There’s no need to stitch together custom scripts to sync multiple tools. It automatically discovers and classifies assets from BigQuery, Cloud Storage, and other connected sources, stitching them into a unified searchable map. Its built-in quality engine runs profiling jobs “serverlessly” and surfaces issues early, preventing downstream problems.
Logical domains add another advantage. Teams can organize data by department, product line, or any meaningful business structure while governance policies cascade automatically. Sensitive information remains protected even when data is shared broadly or crosses projects and clouds. This is autonomous governance in action, where contracts and rules follow the data rather than relying on manual enforcement.
Open formats like Apache Iceberg make this approach portable. By integrating Iceberg, Dataplex Universal Catalog ensures tables stay versioned and compatible across engines and clouds. This supports hybrid lakes and multi-cloud setups without compromising fidelity or audit trails.
Winners and losers in the metadata race
Organizations that get this right will find that agentic AI drives speed and trust, not chaos. Their teams and agents will collaborate fluidly using governed, well-described data products. Natural language queries and autonomous workflows will operate as intended, the metadata layer handling complexity behind the scenes.
Those who neglect this foundation will likely find themselves reactively fixing errors, chasing missing context, and slowing innovation. Hallucinations, compliance slips, and unreliable AI outcomes often stem from weak metadata strategy.
In this new era, the smartest AI still depends on knowing what to trust and where to find it. Metadata is that compass. Dataplex provides the fabric to make it dynamic, secure, and open, your guaranteed ticket to join the AI party with confidence.
Learn more about Google Cloud’s data to AI governance solution here.
{kind=link}
Microsoft brings OpenAI-powered Deep Research to Azure AI Foundry agents 8 Jul 2025, 7:26 am
Microsoft has added OpenAI-developed Deep Research capability to its Azure AI Foundry Agent service to help enterprises integrate research automation into their business applications.
The integration of research automation is made possible by Deep Research API and SDK, which can be used by developers to embed, extend, and orchestrate Deep Research-as-a-service across an enterprise’s ecosystem, including data and existing systems, Yina Arenas, VP of product at Microsoft’s Core AI division, wrote in a blog post.
[ Related: More OpenAi news and insights ]
Developers can use Deep Research to automate large-scale, source-traceable insights, programmatically build and deploy agents as services invokable by apps, workflows, or other agents, and orchestrate complex tasks using Logic Apps, Azure Functions, and Foundry connectors, Arenas added.
Essentially, the new capability is designed to help enterprises enhance their AI agents to conduct deeper analysis of complex data, enabling better decision-making and productivity, said Charlie Dai, vice president and principal analyst at Forrester.
“All major industries will benefit from this, such as investment insights generation for finance, drug discovery acceleration for healthcare, and supply chain optimization for manufacturing,” Dai added.
How does Deep Research work?
Deep Research, at its core, uses a combination of OpenAI and Microsoft technologies, such as o3-deep-research, other GPT models, and Grounding with Bing Search, when integrated into an agent.
When a research request is received by the agent that has Deep Research integrated — whether from a user or another application — the agent taps into GPT-4o and GPT-4.1 to interpret the intent, fill in any missing details, and define a clear, actionable scope for the task.
After the task has been defined, the agent activates the Bing-powered grounding tool to retrieve a refined selection of recent, high-quality web content.
Post this step, the o3-deep-research agent initiates the research process by reasoning through the gathered information and instead of simply summarizing content, it evaluates, adapts, and synthesizes insights across multiple sources, adjusting its approach as new data emerges.
The entire process results in a final output that is a structured report that documents not only the answer, but also the model’s reasoning path, source citations, and any clarifications requested during the session, Arenas explained.
Competition, pricing, and availability
Microsoft isn’t the only hyperscaler offering deep research capability.
“Google Cloud already provides Gemini Deep Research with its Gemini 2.5 Pro. AWS hasn’t offered cloud services on it, but it showcased Bedrock Deep Researcher as a sample application to automate the generation of articles and reports,” Dai said.
Microsoft, itself, offers the deep research capability inside its office suite of applications as Researcher in Microsoft 365 Copilot. OpenAI, too, has added the deep research capability inside its generative AI-based assistant, ChatGPT.
In terms of pricing, Deep Research inside Azure AI Foundry Agent Service will set back enterprises by $10 per million input tokens and $40 per million output tokens for just the 03-deep-research model.
Cached inputs for the model will cost $2.50 per million tokens, the company said.
Further, enterprises will incur separate charges for Grounding with Bing Search and the base GPT model being used for clarifying questions, it added.
{kind=link}
Nvidia doubles down on GPUs as a service 8 Jul 2025, 5:00 am
Nvidia’s recent initiative to dive deeper into the GPU-as-a-service (GPUaaS) model marks a significant and strategic shift that reflects an evolving landscape within the cloud computing market. As enterprises increase their reliance on artificial intelligence (AI) and machine learning (ML) technologies, the demand for high-performance computing has surged. Nvidia’s move is not only timely, but also could prove to be a game-changer, particularly as organizations aim to adopt more cost-effective GPU solutions while still leveraging public cloud resources.
Services like Nvidia’s DGX Cloud Lepton are designed to connect AI developers with a vast network of cloud service providers. Nvidia is offering access to its unparalleled GPU technology through various platforms, allowing enterprises to scale their AI initiatives without significant capital expenditures on hardware.
The crowded GPU cloud market
Nvidia’s innovations are groundbreaking, but the dominant players—Amazon Web Services, Google Cloud, and Microsoft Azure—continue to hold substantial market share. Each of these hyperscalers has developed in-house alternatives, such as AWS’s Trainium, Google’s Tensor processing units (TPUs), and Microsoft’s Maia. This competition, more than mere rivalry, also caters to the unique requirements of different workloads, prompting enterprises to carefully evaluate their GPU needs.
Organizations need to consider that although these solutions offer state-of-the-art GPU capabilities, they often come with significant costs. Accessing GPU cloud services can strain budgets, especially when the rates charged by hyperscalers tend to far exceed the purchase costs of the GPUs themselves. Therefore, it’s vital for enterprises to assess the long-term affordability of their GPU solution choices carefully.
Enterprises seeking to adopt AI and ML are driven to find more cost-effective GPU solutions, and Nvidia’s foray into GPUaaS presents an attractive alternative. Leveraging Nvidia’s technology as a cloud service allows organizations to access GPU resources on a consumption basis, eliminating the need for significant upfront investments while ensuring access to leading-edge technology.
This does not negate the necessity for organizations to evaluate their GPU consumption strategies. In an escalating trend where enterprises are drawn to the benefits of GPUaaS to streamline their operations, decisions made today will have lasting implications for 10 or more years into the future. Given the rapid pace of technology advancement and market shifts, enterprise leaders should consider a strategy that remains adaptable and financially sustainable.
Embracing a multicloud strategy
In the crowded GPU marketplace, enterprises should strongly consider a multicloud strategy. By leveraging multiple cloud providers, organizations can access a diverse range of GPU offerings. They retain the flexibility to assess and select the services and pricing that best meet their evolving needs while keeping options open for future innovation.
A multicloud approach also effectively dispels concerns over price increases or shifts in capabilities. Greater diversity in cloud resources can alleviate risks associated with relying on a single provider. With Nvidia’s DGX Cloud Lepton service and its Industrial AI Cloud tailored for specific industries, companies can harness more specialized GPU resources based on their industry needs, further enhancing their operational efficiencies.
In the pursuit of optimal performance, enterprises should prioritize a best-of-breed cloud strategy that incorporates GPU solutions. This strategy emphasizes selecting cloud providers and GPU services that offer unparalleled capabilities tailored to business needs. By critically evaluating each option based on performance, pricing, and future scalability, businesses can harness the best tools available to meet their needs.
Nvidia’s current offerings serve as a prime example of why a best-of-breed approach is essential. Their focus on specialized services for diverse industrial sectors—like the Industrial AI Cloud—demonstrates an understanding of the unique demands of various industries. As enterprises pursue digital transformation, aligning with providers that deliver tailored solutions can offer competitive advantages and help streamline operations.
Long-term implications
The transition to AI-driven frameworks and the urgency surrounding digital transformation mean that businesses stand at a crossroads where choices must be grounded in readiness for the future. The strategic implications of selecting between hyperscaler offerings and Nvidia’s innovations should not be taken lightly.
Additionally, the cost of GPUs should always be weighed against the operational needs they fulfill. Many organizations are eager to consume GPU services, but it is critical to remember that the cost of these services is often higher than purchasing the hardware outright. A fully informed decision will consider total cost of ownership, performance metrics, and long-term strategic alignment.
As enterprises increasingly turn towards AI and ML technologies, Nvidia’s strategic move into the GPUaaS landscape shapes the future of cloud computing. Although the GPU cloud market may be saturated with options, Nvidia’s moves introduce new avenues for cost-effective and tailored GPU access, positioning Nvidia as a formidable player alongside its hyperscaler competitors.
A multicloud deployment, alongside a commitment to best-of-breed cloud solutions, will empower organizations to make informed decisions that drive long-term success. Ultimately, investing time and resources into these strategic considerations today may define operational efficiency and competitiveness for a decade into the future. As the landscape continues to change, being able to adapt will be key to thriving in the new era of cloud computing.
{kind=link}
How Deutsche Telekom designed AI agents for scale 8 Jul 2025, 5:00 am
Across 10 countries in Europe, Deutsche Telekom serves millions of users, each with their own questions, needs, and contexts. Responding quickly and accurately isn’t just good service; it builds trust, drives efficiency, and impacts the bottom line. But doing that consistently depends on surfacing the right information at the right time, in the right context.
In early 2023, I joined a small cross-functional team formed under an initiative led by our chief product officer, Jonathan Abrahamson. I was responsible for engineering and architecture within the newly formed AI Competence Center (AICC), with a clear goal: Improve customer service across our European operations. As large language models began to show real promise, it became clear that generative AI could be a turning point enabling faster, more relevant, and context-aware responses at scale.
This kicked off a focused effort to solve a core challenge: How to deploy AI-powered assistants reliably across a multi-country ecosystem? That led to the development of LMOS, a sovereign, developer-friendly platform for building and scaling AI agents across Telekom. Frag Magenta OneBOT, our customer-facing assistant for sales and service across Europe, was one of the first major products built on top of it. Today, LMOS supports millions of interactions, significantly reducing resolution time and human handover rates.
Just as important, LMOS was designed to let engineers work with tools they already know to build AI agents and has now reached a point where business teams can define and maintain agents for new use cases. That shift has been key to scaling AI with speed, autonomy, and shared ownership across the organization.
Building a sovereign, scalable agentic AI platform
Amid the urgency, there was also a quiet shift in perspective. This wasn’t just a short-term response; it was an opportunity to build something foundational — a sovereign platform, grounded in open standards, that would let our existing engineering teams build AI applications faster and with more flexibility.
In early 2023, production-ready generative AI applications were rare. Most work was still in early-stage retrieval-augmented generation (RAG) experiments, and the risk of becoming overly dependent on closed third-party platforms was hard to ignore. So instead of assembling a stack from scattered tools, we focused on the infrastructure itself, something that could grow into a long-term foundation for scalable, enterprise-grade AI agents.
It wasn’t just about solving the immediate problem. It was about designing for what would come next.
LMOS: Language Model Operating System
What started as a focused effort on chatbot development quickly surfaced deeper architectural challenges. We experimented with frameworks like LangChain, a popular framework for integrating LLMs into applications, and fine-tuned Dense Passage Retrieval (DPR) models for German-language use cases. These early prototypes helped us learn fast, but as we moved beyond experimentation, cracks started to show.
The stack became hard to manage. Memory issues, instability, and a growing maintenance burden made it clear this approach wouldn’t scale. At the same time, our engineers were already deeply familiar with Deutsche Telekom’s JVM-based systems, APIs, and tools. Introducing unfamiliar abstractions would have slowed us down.
So we shifted focus. Instead of forcing generative AI into fragmented workflows, we set out to design a platform that felt native to our existing environment. That led to LMOS, the Language Model Operating System, a sovereign PaaS for building and scaling AI agents across Deutsche Telekom. LMOS offers a Heroku-like experience for agents, abstracting away life-cycle management, deployment models, classifiers, observability, and scaling while supporting versioning, multitenancy, and enterprise-grade reliability.
At the core of LMOS is Arc, a Kotlin-based framework for defining agent behavior through a concise domain-specific language (DSL). Engineers could build agents using the APIs and libraries they already knew. No need to introduce entirely new stacks or rewire development workflows. At the same time, Arc was built to integrate cleanly with existing data science tools, making it easy to plug in custom components for evaluation, fine-tuning, or experimentation where needed.
Arc also introduced ADL (Agent Definition Language), which allows business teams to define agent logic and workflows directly, reducing the need for engineering involvement in every iteration and enabling faster collaboration across roles. Together, LMOS Arc, and ADL helped bridge the gap between business and engineering, while integrating cleanly with open standards and data science tools, accelerating how agents were built, iterated, and deployed across the organization.
Vector search and the role of contextual retrieval
By grounding LMOS in open standards and avoiding unnecessary architectural reinvention, we built a foundation that allowed AI agents to be designed, deployed, and scaled across geographies. But platform infrastructure alone wasn’t enough. Agent responses often depend on domain knowledge buried in documentation, policies, and internal data sources and that required retrieval infrastructure that could scale with the platform.
We built structured RAG pipelines powered by vector search to provide relevant context to agents at run time. Choosing the right vector store was essential. After evaluating various options from traditional database extensions to full-featured, dedicated vector systems we selected Qdrant, an open-source, Rust-based vector database that aligned with our operational and architectural goals. Its simplicity, performance, and support for multitenancy and metadata filtering made it a natural fit, allowing us to segment data sets by country, domain, and agent type, ensuring localized compliance and operational clarity as we scaled across markets.
Wurzel: Rooting retrieval in reusability
To support retrieval at scale, we also built Wurzel, an open-source Python ETL (extract, transform, load) framework tailored for RAG. Named after the German word for “root,” Wurzel enabled us to decentralize RAG workflows while standardizing how teams prepared and managed unstructured data. With built-in support for multitenancy, job scheduling, and back-end integrations, Wurzel made retrieval pipelines reusable, consistent, and easy to maintain across diverse teams and markets.
Wurzel also gave us the flexibility to plug in the right tools for the job without fragmenting the architecture or introducing bottlenecks. In practice, this meant faster iteration, shared infrastructure, and fewer one-off integrations.
Agent building with LMOS Arc and semantic routing
Agent development in LMOS starts with Arc. Engineers use its DSL to define behavior, connect to APIs, and deploy agents using microservice-style workflows. Once built, agents are deployed to Kubernetes environments via LMOS, which handles versioning, monitoring, and scaling behind the scenes.
But defining behavior wasn’t enough. Agents needed access to relevant knowledge to respond intelligently. Vector-powered retrieval pipelines fed agents with context from internal documentation, FAQs, and structured policies. Qdrant’s multi-tenant vector store provided localized, efficient, and compliant data access.
To make agent collaboration more effective, we also introduced semantic routing. Using embeddings and vector similarity, agents could classify and route customer queries, complaints, billing, and sales without relying entirely on LLMs. This brought greater structure, interpretability, and precision to how agents operated together.
Together, Arc, Wurzel, Qdrant, and the broader LMOS platform enabled us to build agents quickly, operate them reliably, and scale them across business domains without compromising developer speed or enterprise control.
‘Heroku’ for agents
I often describe LMOS as “Heroku for agents.” Just like Heroku abstracted the complexity of deploying web apps, LMOS abstracts the complexity of running production-grade AI agents. Engineers don’t need to manage deployment models, classifiers, monitoring, or scaling — LMOS handles all that.
Today, LMOS powers customer-facing agents, including the Frag Magenta OneBOT assistant. We believe this is one of the first multi-agent platforms to go live, with planning and deployment beginning before OpenAI released its agent SDK in early 2024. It is arguably the largest enterprise deployment of multiple AI agents in Europe, currently supporting millions of conversations across Deutsche Telekom’s markets.
The time required to develop a new agent has dropped to a day or less, with business teams now able to define and update operating procedures without relying on engineers. Handovers to human support for API-triggering Arc agents are around 30%, and we expect this to decrease as knowledge coverage, back-end integration, and platform maturity continue to improve.
Scaling sovereign AI with open source and community collaboration
Looking ahead, we see the potential applications of LMOS continuing to grow especially as agentic computing and retrieval infrastructure mature. From the beginning, we built LMOS on open standards and infrastructure primitives like Kubernetes, ensuring portability across developer machines, private clouds, and data centers.
In that same spirit, we decided to contribute LMOS to the Eclipse Foundation, allowing it to evolve with community participation and remain accessible to organizations beyond our own. As more teams begin to understand how semantic search and structured retrieval ground AI in trusted information, we expect interest in building on LMOS to increase.
What’s guided us so far isn’t just technology. It’s been a focus on practical developer experience, interoperable architecture, and hard-won lessons from building in production. That mindset has helped shift us from model-centric experimentation toward a scalable, open, and opinionated AI stack, something we believe is critical for bringing agentic AI into the real world, at enterprise scale.
Arun Joseph is former engineering and architecture lead at Deutsche Telecom.
—
Generative AI Insights provides a venue for technology leaders to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
{kind=link}
What you absolutely cannot vibe code right now 8 Jul 2025, 5:00 am
LinkedIn has become the new Twitter now that Twitter is… well, X. LinkedIn is a place of shockingly bold claims. One person claimed to be so confident in agentic development that they are going to generate their own operating system on the level of iOS or Android. Ever the iconoclast, I pointed out that it was not possible they would ever publish or install it.
Another pitchman promoted the idea that large language models (LLMs) are producing more and higher-quality pull requests (PRs) than humans, based on the number of PRs on a tool and their acceptance rate. I pointed out that this isn’t possibly true. I wasn’t motivated to write something to classify them, but I sampled about 20. It turned out that the dashboard our enthusiast was looking at is picking up mainly people’s private projects, where they are basically auto-approving whatever the LLMs send (YOLO style), and a large number of the commits are LLM-style “everything that didn’t need to be said” documentation. Or as one person accepting the merge put it, “Feels like lot of garbage added — but looks relavant [sic]. Merging it as baseline, will refine later (if applicable).”
Don’t get me wrong, I think you should learn to use LLMs in your everyday coding process. And if any statistics or reported numbers are accurate, most of you are at least to some degree. However, I also think it is essential not to misrepresent what LLMs can currently do and what is beyond their capabilities at this point.
As mentioned in previous posts, all the current LLM-based tools are somewhat limiting and, frankly, annoying. So I’m writing my own. Honestly, I expected to be able to flat-out vibe code and generate the patch system. Surely the LLM knows how to make a system to accept patches from an LLM. It turns out that nothing could be further from the truth. First of all, diffing and patching are one of those deceptively complex areas of computing. It was a lesson I forgot. Secondly, writing a patch system to accept patches from something that isn’t very good at generating clean patches is much more complicated than writing one for something that produces patches with a clean algorithm. Generating a patch system that accepts patches from multiple models, each with its own quirks, is very challenging. It was so hard that I gave up and decided to find the best one and just copy it.
Trial and errors
The best patch system is Aider AI’s patch system. They publish benchmarks for every LLM, evaluating how well they generate one-shot patches. Their system isn’t state-of-the-art; it doesn’t even use tool calls. It’s largely hand-rolled, hard-won Python. The obvious thing to do was to use an LLM to port this to TypeScript, enabling me to use it in my Visual Studio Code plugin. That should be simple. Aside from that part, Aider had already figured out it’s a bunch of string utilities. There is no Pandas. There is no MATLAB. This is simply a string replacement.
I also wanted to benchmark OpenAI’s o3 running in Cursor vs. Anthropic’s Claude Opus 4 running in Claude Code. I had both of them create plans and critique each other’s plans. To paraphrase o3, Opus’s plan was overcomplicated and destined to fail. To paraphrase Claude Opus, o3’s code was too simplistic, and the approach pushed all the hard stuff to the end and was destined to fail.
Both failed miserably. In the process, I lost faith in Claude Opus to notice a simple problem and created a command-line tool I called asko3 (which later became “o3Helper”) so that Claude could just ask o3 before it made any more mistakes. I lost faith in Cursor being able to keep their back end running and reply to any requests, so o3 in Cursor lost by default. Onward with the next combo, standalone Claude Opus 4 advised by standalone o3.
That plan also failed miserably. o3 suggested that Opus had created a “cargo cult” implementation (its term, not mine) of what Aider’s algorithm did. It suggested that the system I use for creating plans was part of the problem. Instead, I created a single document plan. Then I had o3 do most of the implementation (from inside Claude Code). It bungled it completely. I had Claude ask o3 to review its design without telling it that it was its own design. It eviscerated it. Claude called the review “brutal but accurate.”
Finally, I still needed my patch system to work and really didn’t care to hand-code the TypeScript. I had Claude copy the comments over from Aider’s implementation and create a main method that served as a unit test. Then I had Claude port each method over one at a time. When something failed, I suggested a realignment method by method. I reviewed each decision, and then we reviewed the entire process — success. This was as far from vibe coding as you can be. It wasn’t much faster than typing it myself. This was just a patch algorithm.
The fellow hoping to “generate an operating system” faces many challenges. LLMs are trained on a mountain of CRUD (create, read, update, delete) code and web apps. If that is what you are writing, then use an LLM to generate virtually all of it — there is no reason not to. If you get down into the dirty weeds of an algorithm, you can generate it in part, but you’ll have to know what you’re doing and constantly re-align it. It will not be simple.
Good at easy
This isn’t just me saying this, this is what studies show as well. LLMs fail at hard and medium difficulty problems where they can’t stitch together well-known templates. They also have a half-life and fail when problems get longer. Despite o3’s (erroneous in this case) supposition that my planning system caused the problem, it succeeds most of the time by breaking up the problem into smaller parts and forcing the LLM to align to a design without having to understand the whole context. In short I give it small tasks it can succeed at. However, one reason the failed is that despite all the tools created there are only about 50 patch systems out there in public code. With few examples to learn from, they inferred that unified diffs might be a good way (they aren’t generally). For web apps, there are many, many examples. They know that field very well.
What to take from this? Ignore the hype. LLMs are helpful, but truly autonomous agents are not developing production-level code at least not yet. LLMs do best at repetitive, well-understood areas of software development (which are also the most boring). LLMs fail at novel ideas or real algorithmic design. They probably won’t (by themselves) succeed anywhere there aren’t a lot of examples in GitHub.
What not to take from this? Don’t conclude that LLM’s are totally useless, and that you must be a software craftsman and lovingly hand-code your CSS and HTML and repetitive CRUD code like your pappy before you. Don’t think that LLMs are useless if you are working on a hard problem. They can help; they just can’t implement the whole thing for you. I didn’t have to search for the name of every TypeScript string library that matched the Python libraries. The LLM did it for me. Had I started with that as a plan, it would have gone quickly.
If you’re doing a CRUD app, doing something repetitive, or tackling a problem domain where there are lots of training materials out there, you can rely on the LLMs. If you’re writing an operating system, then you will need to know how to write an operating system and the LLM can type for you. Maybe it can do it in Rust where you did it last time in C, because you know all about how to write a completely fair scheduler. If you’re a full-stack Node.js developer, you will not be (successfully) ChatGPT-ing an iOS alternative because you are mad at Apple.
{kind=link}
Deno 2.4 restores JavaScript bundling subcommand 7 Jul 2025, 6:19 pm
Deno 2.4, the latest version of Deno Land’s JavaScript and TypeScript runtime, has been released with the restoration of the deno bundle subcommand for creating single-file JavaScript bundles.
Announced July 2, Deno 2.4 also stabilizes Deno’s built-in OpenTelemetry support for collecting and exporting telemetry data, and offers easier dependency management, Deno Land said. Current users of Deno can upgrade to Deno 2.4 by running the deno upgrade command in their terminal. Installation instructions for new users can be found here.
Deno 2.4 restores the deno bundle subcommand for creating single-file JavaScript bundles from JavaScript or TypeScript. This command supports both server-side and browser platforms and works with NPM and JSR (JavaScript Registry) dependencies. Automatic tree-shaking and minification are supported via the esbuild bundler. Future plans call for adding a runtime to make bundling available programmatically. Additionally, plugins are to be added for customizing how the bundler processes modules during the build process.
Also in Deno 2.4, OpenTelemetry support, which auto-instruments the collection of logs, metrics, and traces for a project, is now stable. OpenTelemetry support was introduced in Deno 2.2 in February. Improving dependency management in Deno 2.4, a new deno update subcommand lets developers update dependencies to the latest versions. The command will update NPM and JSR dependencies listed in deno.json or package.json files to the latest semver-compatible versions.
Elsewhere in Deno 2.4:
- The Deno environment now can be modified with a new
--preloadflag that executes code before a main script. This is useful when a developer is building their own platform and needs to modify globals, load data, connect to databases, install dependencies, or provide other APIs. - Node global variables were added, including
Buffer,global,setImmediate, andclearImmediate. An--unstable-node-globalsflag is no longer needed for exposing this set of globals. - Support for Node.js APIs has again been improved.
- A new environment variable,
DENO_COMPAT=1, was introduced that will tell Deno to enable a set of flags to improve ergonomics when using Deno in package.json projects. fetchnow works over Unix and Vsock sockets.
{kind=link}
Arriving at ‘Hello World’ in enterprise AI 7 Jul 2025, 5:00 am
Brendan Falk didn’t set out to become a cautionary tale. Three months after leaving AWS to build what he called an “AI-native Palantir,” he’s pivoting away from enterprise AI projects altogether. In a widely shared X thread, Falk offers some of the reasons: 18-month sales cycles, labyrinthine integrations, and post-sale maintenance that swallows margins. In other words, all the assembly required to make AI work in the enterprise, regardless of the pseudo instant gratification that consumer-level ChatGPT prompts may return.
Just ask Johnson & Johnson, which recently culled 900 generative AI pilots, keeping only the 10% to 15% that delivered real value (though it continues to struggle to anticipate which will yield fruit). Look to data from IBM Consulting, which says just 1% of companies manage to scale AI beyond proof of concept. Worried? Don’t be. After all, we’ve been here before. A decade ago, I wrote about how enterprises struggled to put “big data” to use effectively. Eventually, we got there, and it’s that “eventually” we need to keep in mind as we get caught up in the mania of believing that AI is changing everything everywhere all at once.
Falk’s three lessons
Though Falk has solid startup experience (he cofounded and ran Fig before its acquisition by Amazon), he was unprepared for the ugly stodginess of the enterprise. His findings:
- Enterprise AI sells like middleware, not SaaS. You’re not dropping an API into Slack; you’re rewiring 20-year-old ERP systems. Procurement cycles are long and bespoke scoping kills product velocity. Then there’s the potential for things to go very wrong. “Small deals are just as much work as larger deals, but are just way less lucrative,” Falk says. Yep.
- Systems integrators capture the upside. By the time Accenture or Deloitte finishes the rollout, your startup’s software is a rounding error on the services bill.
- Maintenance is greater than innovation. Enterprises don’t want models that drift; they want uptime, and AI’s non-deterministic “feature” is very much a bug for the enterprise. “Enterprise processes have countless edge cases that are incredibly difficult to account for up front,” he says. Your best engineers end up writing compliance documentation instead of shipping features.
These aren’t new insights, per se, but they’re easy to forget in an era when every slide deck says “GPT-4o will change everything.” It will, but it currently can’t for most enterprises. Not in the “I vibe-coded a new app; let’s roll it into production” sort of way. That works on X, but not so much in serious enterprises.
Palantir’s “told-you-so” moment
Ted Mabrey, Palantir’s head of commercial, couldn’t resist dunking on Falk: “If you want to build the next Palantir, build on Palantir.” He’s not wrong. Palantir has productized the grunt work—data ontologies, security models, workflow plumbing—that startups discover the hard way.
Yet Mabrey’s smugness masks a bigger point: Enterprises don’t buy AI platforms; they buy outcomes. Palantir succeeds when it shows an oil company how to shave days off planning the site for a new well, or helps a defense ministry fuse sensor data into targeting decisions. The platform is invisible.
Developers, not boardrooms, will mainstream AI
In prior InfoWorld columns, I’ve argued that technology adoption starts with “bottom-up” developer enthusiasm and then bubbles upward. Kubernetes, MongoDB, even AWS followed that path. Falk’s experience proves that the opposite route—“top-down AI transformation” pitched to CIOs—remains a quagmire.
The practical route looks like this:
- Start with a narrow, high-value workflow. Johnson & Johnson’s “Rep Copilot” is a sales assistant not a moon shot. A narrow scope makes ROI obvious.
- Ship fast, measure faster. Enterprises are comfortable killing projects that don’t move KPIs. Make it easy for them.
- Expose an API, earn love. Developers don’t read Gartner reports; they copy code from GitHub. Give them something to build with and they’ll drag procurement along later.
What’s next
Falk says his team will now “get into the arena” by launching products with shorter feedback loops. That’s good. Build for developers, price like a utility, and let usage (not enterprise promises) guide the road map. The big money will come from the Fortune 500 eventually, but only after thousands of engineers have already smuggled your API through the firewall.
Enterprise AI transformation isn’t dead; it’s just repeating history. When visionary decks meet ossified org charts, physics wins. The lesson is to respect that and abstract away the integration sludge, price for experimentation, and, above all, court the builders who actually make new tech stick.
Falk’s pivot is a reminder that the fastest way into the enterprise is often through the side door of developer adoption, not the fancy lobby of the boardroom.
{kind=link}
OutSystems Mentor: An AI-powered digital assistant for the entire SDLC 7 Jul 2025, 5:00 am
Today’s developers navigate a complex landscape marked by slow development cycles, skills gaps, talent shortages, high customization costs, and tightening budgets. The burden of maintaining legacy systems, while adapting to business evolution, adds further strain. With the pressure to drive ROI from software investments, organizations often find themselves caught in the “build vs. buy” dilemma, only to find that off-the-shelf software falls short of meeting their digital transformation needs or delivering a competitive advantage.
At the same time, the recent AI coding assistants and AI platforms that promise to generate full-stack applications often fall short. Ungoverned generative AI (genAI) generates as many risks as it does lines of code, including hallucinations, security holes, architectural flaws, and unexcutable code. In fact, 62% of IT professionals report that using genAI for coding has raised new concerns around security and governance.
It’s the perfect storm for IT teams, but there is hope. A new generation of AI-powered low-code development tools addresses these challenges head-on. Designed to help teams accelerate enterprise application development, free up time for innovation, and maintain observability and governance, offerings like OutSystems Mentor reimagine the software development life cycle (SDLC) altogether.
Introducing OutSystems Mentor
In October 2024, OutSystems introduced Mentor, an AI-powered digital assistant for the entire SDLC. Combining low-code, generative AI, and AI-driven guidance, Mentor represents a major step forward in how software is created, managed, and updated—all within the OutSystems Developer Cloud (ODC) platform.
Mentor is an AI-powered team member trained to support or complete sequential tasks and even entire processes. Integrating generative AI, natural language processing, industry-leading AI models, and machine learning, Mentor provides intelligent, context-aware support across the development workflow, accelerating the creation of full-stack enterprise applications that are easy to maintain via low-code. In doing so, Mentor helps teams maintain a competitive edge without the high costs associated with traditional coding, and without having to maintain hard-to-understand code created by other developers, AI co-pilots, or conversational app builders.
Mentor is fully integrated with the OutSystems Developer Cloud (ODC), allowing organizations to scale from prototype to enterprise-grade deployment while maintaining control and reducing technical debt. With ODC as the foundation, Mentor enables a more efficient, secure, and scalable approach to AI-driven development, supporting teams in delivering high-quality applications faster and with greater consistency.
Generate fully functional, scalable applications
From discovery to rapid prototyping, IT teams can use Mentor to validate ideas and refine initial designs, ensuring alignment before committing to full-scale development. This early-stage clarity helps save time and maximize the impact of every effort, while reducing friction between business and technical teams by creating a shared understanding from day one.
Mentor’s development process is intuitive. Developers describe the application they need, whether through a short prompt or a detailed requirements document. Mentor then combines this input with contextual awareness from the user’s environment, automatically generating an initial version of the app. This includes front-end functionality, data models, and embedded business logic tailored to the organization’s ecosystem.
Further differentiating itself from other AI coding tools, Mentor identifies relevant entities from existing applications or external systems, along with key roles, attributes, records, and workflows needed to generate the app, giving users a head start on development that’s integrated and in tune with real-world needs and organizational context.
Improve, iterate, and evolve applications with AI-powered suggestions
Creating a minimum viable product (MVP) is arguably the most challenging hurdle to overcome in application development. Constant improvement and quick iterations are critical because they ensure products, processes, and services remain relevant, competitive, and aligned with evolving customer needs.
The journey from MVP to production-ready is accelerated with Mentor’s intelligent App Editor, which analyzes an application’s structure and data model and offers AI-powered suggestions for real-time improvements. Whether optimizing performance, refining UX, or improving maintainability, developers can level up their applications with speed, confidence, and precision, reducing rework and accelerating delivery.
Developers also have the option to step outside the App Editor for any additional editing and customization using the ODC Studio, the integrated development environment (IDE) for OutSystems Developer Cloud. Any changes made to the application are reflected back in App Editor, and users can continue refining their app with AI-driven suggestions, enabling a fluid workflow.
Embed AI agents within apps to automate digital interactions
Also built on ODC, OutSystems AI Agent Builder automates tasks with customizable intelligent agents and integrates them into OutSystems Developer Cloud apps to leverage generative AI. This enables IT teams to quickly and securely infuse apps with genAI agents, bringing conversational agentic interactions to life in minutes, without any coding or deep AI expertise.
AI Agent Builder streamlines the process of AI integration, making powerful functionality accessible to a broader range of teams. With a combination of large language models and retrieval-augmented generation, the AI Agent Builder allows users to create intelligent agents (backed by the organization’s proprietary knowledge) via simple, natural language inputs. By enhancing applications with intelligent, conversational interfaces, the platform drives real outcomes, such as when an AI customer service agent can automatically address and resolve customer issues.
IT teams using OutSystems AI Agent Builder gain full control and access to models, proprietary data, and agents in a single, scalable platform. With built-in monitoring tools, the AI Agent Builder enables continuous performance tracking and optimization, ensuring agents not only adapt and improve over time but also deliver accurate, trustworthy results aligned with evolving business goals. Organizations can scale AI capabilities confidently, without sacrificing oversight or accountability.
Validate and maintain applications through AI-powered code reviews
Before any application is deployed to production, Mentor validates and maintains applications via AI-powered code reviews across every layer of the stack. Doing so ensures all applications meet the highest possible standards for development, security, performance, architecture, and long-term maintainability. Catching issues early and enforcing consistent standards also helps teams avoid costly rework and technical debt.
Taking a proactive approach to quality assurance, Mentor continuously scans applications every 12 hours, flagging potential issues or security risks within a unified dashboard. This ongoing monitoring ensures that quality and compliance are embedded into the development life cycle, helping teams stay ahead of issues and deliver software with confidence.
Shaping the future of AI app and agent development
At this inflection point, software development is undergoing a transformative shift, enabling faster, more efficient, and smarter processes. With the integration of AI-driven low-code tools like OutSystems Mentor, development teams can harness the power of automation, intelligent insights, and SDLC recommendations, accelerating innovation and staying ahead in an ever-evolving digital landscape.
AI isn’t replacing developers—it’s handling the grunt work, from troubleshooting code to enabling rapid app creation, freeing developers to be creative orchestrators and grow into leadership roles. But this is only the beginning.
As teams grow more comfortable integrating AI into their development processes, the next step is embracing AI agents. OutSystems is actively building towards this future, where autonomous AI agents take on more complex tasks and interact with systems independently, driving business processes and decision-making.
At OutSystems, our vision is to empower every company to innovate through software. OutSystems Mentor and our forthcoming AI-powered products are testaments to this vision, revolutionizing how applications are built and orchestrated, driving faster, smarter innovation at scale.
Luis Blando is chief product and technology officer at OutSystems.
—
New Tech Forum provides a venue for technology leaders to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
Advanced unit testing with JUnit 5, Mockito, and Hamcrest 7 Jul 2025, 5:00 am
In this second half of a two-part introduction to JUnit 5, we’ll move beyond the basics and learn how to test more complicated scenarios. In the previous article, you learned how to write tests using the @Test and @ParameterizedTest annotations, validate test results using JUnit 5’s built-in assertions, and work with JUnit 5 lifecycle annotations and tags. In this article, we’ll focus more on integrating external tools with JUnit 5.
You’ll learn:
- How to use Hamcrest to write more flexible and readable test cases.
- How to use Mockito to create mock dependencies that let you simulate any scenario you want to test.
- How to use Mockito spies to ensure that method calls return the correct values, as well as verify their behavior.
Using JUnit 5 with an assertions library
For most circumstances, the default assertions methods in JUnit 5 will meet your needs. But if you would like to use a more robust assertions library, such as AssertJ, Hamcrest, or Truth, JUnit 5 provides support for doing so. In this section, you’ll learn how to integrate Hamcrest with JUnit 5.
Hamcrest with JUnit 5
Hamcrest is based on the concept of a matcher, which can be a very natural way of asserting whether or not the result of a test is in a desired state. If you have not used Hamcrest, examples in this section should give you a good sense of what it does and how it works.
The first thing we need to do is add the following additional dependency to our Maven POM file (see the previous article for a refresher on including JUnit 5 dependencies in the POM):
org.hamcrest hamcrest 3.0 test
When we want to use Hamcrest in our test classes, we need to leverage the org.hamcrest.MatcherAssert.assertThat method, which works in combination with one or more of its matchers. For example, a test for String equality might look like this:
assertThat(name, is("Steve"));
Or, if you prefer:
assertThat(name, equalTo("Steve"));
Both matchers do the same thing—the is() method in the first example is just syntactic sugar for equalTo().
Hamcrest defines the following common matchers:
- Objects:
equalTo, hasToString, instanceOf, isCompatibleType, notNullValue, nullValue, sameInstance - Text:
equalToIgnoringCase, equalToIgnoringWhiteSpace, containsString, endsWith, startsWith - Numbers:
closeTo, greaterThan, greaterThanOrEqualTo, lessThan, lessThanOrEqualTo - Logical:
allOf, anyOf, not - Collections:
array(compare an array to an array of matchers),hasEntry, hasKey, hasValue, hasItem, hasItems, hasItemInArray
The following code sample shows a few examples of using Hamcrest in a JUnit 5 test class.
Listing 1. Using Hamcrest in a JUnit 5 test class (HamcrestDemoTest.java)
package com.javaworld.geekcap.hamcrest;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import static org.hamcrest.MatcherAssert.assertThat;
import static org.hamcrest.Matchers.*;
class HamcrestDemoTest {
@Test
@DisplayName("String Examples")
void stringExamples() {
String s1 = "Hello";
String s2 = "Hello";
assertThat("Comparing Strings", s1, is(s2));
assertThat(s1, equalTo(s2));
assertThat("ABCDE", containsString("BC"));
assertThat("ABCDE", not(containsString("EF")));
}
@Test
@DisplayName("List Examples")
void listExamples() {
// Create an empty list
List list = new ArrayList();
assertThat(list, isA(List.class));
assertThat(list, empty());
// Add a couple items
list.add("One");
list.add("Two");
assertThat(list, not(empty()));
assertThat(list, hasSize(2));
assertThat(list, contains("One", "Two"));
assertThat(list, containsInAnyOrder("Two", "One"));
assertThat(list, hasItem("Two"));
}
@Test
@DisplayName("Number Examples")
void numberExamples() {
assertThat(5, lessThan(10));
assertThat(5, lessThanOrEqualTo(5));
assertThat(5.01, closeTo(5.0, 0.01));
}
}
One thing I like about Hamcrest is that it is very easy to read. For example, “assert that name is Steve,” “assert that list has size 2,” and “assert that list has item Two” all read like regular sentences in the English language. In Listing 1, the stringExamples test first compares two Strings for equality and then checks for substrings using the containsString() method. An optional first argument to assertThat() is the “reason” for the test, which is the same as the message in a JUnit assertion and will be displayed if the test fails. For example, if we added the following test, we would see the assertion error below it:
assertThat("Comparing Strings", s1, is("Goodbye"));
java.lang.AssertionError: Comparing Strings
Expected: is "Goodbye"
but: was "Hello"
Also note that we can combine the not() logical method with a condition to verify that a condition is not true. In Listing 1, we check that the ABCDE String does not contain substring EF using the not() method combined with containsString().
The listExamples creates a new list and validates that it is a List.class, and that it’s empty. Next, it adds two items, then validates that it is not empty and contains the two elements. Finally, it validates that it contains the two Strings, "One" and "Two", that it contains those Strings in any order, and that it has the item "Two".
Finally, the numberExamples checks to see that 5 is less than 10, that 5 is less than or equal to 5, and that the double 5.01 is close to 5.0 with a delta of 0.01, which is similar to the assertEquals method using a delta, but with a cleaner syntax.
If you’re new to Hamcrest, I encourage you to learn more about it from the Hamcrest website.
Introduction to Mock objects with Mockito
Thus far, we’ve only reviewed testing simple methods that do not rely on external dependencies, but this is far from typical for large applications. For example, a business service probably relies on either a database or web service call to retrieve the data that it operates on. So, how would we test a method in such a class? And how would we simulate problematic conditions, such as a database connection error or timeout?
The strategy of mock objects is to analyze the code behind the class under test and create mock versions of all its dependencies, creating the scenarios that we want to test. You can do this manually—which is a lot of work—or you could leverage a tool like Mockito, which simplifies the creation and injection of mock objects into your classes. Mockito provides a simple API to create mock implementations of your dependent classes, inject the mocks into your classes, and control the behavior of the mocks.
The example below shows the source code for a simple repository.
Listing 2. Example repository (Repository.java)
package com.javaworld.geekcap.mockito;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.List;
public class Repository {
public List getStuff() throws SQLException {
// Execute Query
// Return results
return Arrays.asList("One", "Two", "Three");
}
}
This next listing shows the source code for a service that uses this repository.
Listing 3. Example service (Service.java)
package com.javaworld.geekcap.mockito;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class Service {
private Repository repository;
public Service(Repository repository) {
this.repository = repository;
}
public List getStuffWithLengthLessThanFive() {
try {
return repository.getStuff().stream()
.filter(stuff -> stuff.length()
The Repository class in Listing 2 has a single method, getStuff, that would presumably connect to a database, execute a query, and return the results. In this example, it simply returns a list of three Strings. The Service class in Listing 3 receives the Repository through its constructor and defines a single method, getStuffWithLengthLessThanFive, which returns all Strings with a length less than 5. If the repository throws an SQLException, then it returns an empty list.
Unit testing with JUnit 5 and Mockito
Now let’s look at how we can test our service using JUnit 5 and Mockito. Listing 4 shows the source code for a ServiceTest class.
Listing 4. Testing the service (ServiceTest.java)
package com.javaworld.geekcap.mockito;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.Mockito;
import org.mockito.junit.jupiter.MockitoExtension;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.List;
@ExtendWith(MockitoExtension.class)
class ServiceTest {
@Mock
Repository repository;
@InjectMocks
Service service;
@Test
void testSuccess() {
// Setup mock scenario
try {
Mockito.when(repository.getStuff()).thenReturn(Arrays.asList("A", "B", "CDEFGHIJK", "12345", "1234"));
} catch (SQLException e) {
e.printStackTrace();
}
// Execute the service that uses the mocked repository
List stuff = service.getStuffWithLengthLessThanFive();
// Validate the response
Assertions.assertNotNull(stuff);
Assertions.assertEquals(3, stuff.size());
}
@Test
void testException() {
// Setup mock scenario
try {
Mockito.when(repository.getStuff()).thenThrow(new SQLException("Connection Exception"));
} catch (SQLException e) {
e.printStackTrace();
}
// Execute the service that uses the mocked repository
List stuff = service.getStuffWithLengthLessThanFive();
// Validate the response
Assertions.assertNotNull(stuff);
Assertions.assertEquals(0, stuff.size());
}
}
The first thing to notice about this test class is that it is annotated with @ExtendWith(MockitoExtension.class). The @ExtendWith annotation is used to load a JUnit 5 extension. JUnit defines an extension API, which allows third-party vendors like Mockito to hook into the lifecycle of running test classes and add additional functionality. The MockitoExtension looks at the test class, finds member variables annotated with the @Mock annotation, and creates a mock implementation of those variables. It then finds member variables annotated with the @InjectMocks annotation and attempts to inject its mocks into those classes, using either construction injection or setter injection.
In this example, MockitoExtension finds the @Mock annotation on the Repository member variable, so it creates a mock implementation and assigns it to the repository variable. When it discovers the @InjectMocks annotation on the Service member variable, it creates an instance of the Service class, passing the mock Repository to its constructor. This allows us to control the behavior of the mock Repository class using Mockito’s APIs.
In the testSuccess method, we use the Mockito API to return a specific result set when its getStuff method is called. The API works as follows:
- First, the Mockito::when method defines the condition, which in this case is the invocation of the
repository.getStuff()method. - Then, the
when()method returns anorg.mockito.stubbing.OngoingStubbinginstance, which defines a set of methods that determine what to do when the specified method is called. - Finally, in this case, we invoke the
thenReturn()method to tell the stub to return a specificListofStrings.
At this point, we have a Service instance with a mock Repository. When the Repository’s getStuff method is called, it returns a list of five known strings. We invoke the Service’s getStuffWithLengthLessThanFive() method, which will invoke the Repository’s getStuff() method, and return a filtered list of Strings whose length is less than five. We can then assert that the returned list is not null and that the size of it is three. This process allows us to test the logic in the specific Service method, with a known response from the Repository.
The testException method configures Mockito so that when the Repository’s getStuff() method is called, it throws an SQLException. It does this by invoking the OngoingStubbing object’s thenThrow() method, passing it a new SQLException instance. When this happens, the Service should catch the exception and return an empty list.
Mocking is powerful because it allows us to simulate scenarios that would otherwise be difficult to replicate. For example, you may invoke a method that throws a network or I/O error and write code to handle it. But unless you turn off your WiFi or disconnect an external drive at the exact right moment, how do you know the code works? With mock objects, you can throw those exceptions and prove that your code handles them properly. With mocking, you can simulate rare edge cases of any type.
Introduction to Mockito spies
In addition to mocking the behavior of classes, Mockito allows you to verify their behavior. Mockito provides “spies” that watch an object so you can ensure specific methods are called with specific values. For example, you may want to ensure that, when you call a service, it makes a specific call to a repository. Or you might want to ensure that it does not call the repository but rather loads the item from a cache. Using Mockito spies lets you not only validate the response of a method call but ensure the method does what you expect.
This may seem a little abstract, so let’s start with a simple example that works with a list of Strings. Listing 5 shows a test method that adds two Strings to a list and then checks the size of the list after each addition. We’ll then verify that the list’s add() method is called for the two Strings, and that the size() method is called twice.
Listing 5. Testing a List with spies (SimpleSpyTest.java)
package com.javaworld.geekcap.mockito;
import static org.mockito.Mockito.atLeastOnce;
import static org.mockito.Mockito.never;
import static org.mockito.Mockito.times;
import static org.mockito.Mockito.verify;
import java.util.ArrayList;
import java.util.List;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.Spy;
import org.mockito.junit.jupiter.MockitoExtension;
@ExtendWith(MockitoExtension.class)
public class SimpleSpyTest {
@Spy
List stringList = new ArrayList();
@Test
public void testStringListAdd() {
// Add an item to the list and verify that it has one element
stringList.add("One");
Assertions.assertEquals(1, stringList.size());
// Add another item to the list and verify that it has two elements
stringList.add("Two");
Assertions.assertEquals(2, stringList.size());
// Verify that add was called with arguments "One" and "Two"
verify(stringList).add("One");
verify(stringList).add("Two");
// Verify that add was never called with an argument of "Three"
verify(stringList, never()).add("Three");
// Verify that the size() method was called twice
verify(stringList, times(2)).size();
// Verify that the size() method was called at least once
verify(stringList, atLeastOnce()).size();
}
}
Listing 5 starts by defining an ArrayList of Strings and annotates it with Mockito’s @Spy annotation. The @Spy annotation tells Mockito to watch and record every method called on the annotated object. We add the String "One" to the list, assert that its size is 1, and then add the String "Two" and assert that its size is 2.
After we do this, we can use Mockito to verify everything we did. The org.mockito.Mockito.verify() method accepts a spied object and returns a version of the object that we can use to verify that specific method calls were made. If those methods were called, then the test continues, and if those methods were not called, the test case fails. For example, we can verify that add("One") was called as follows:
If the String list’s add() method is called with an argument of "One" then the test continues to the next line, and if it’s not the test fails. After verifying "One" and "Two" are added to the list, we verify that add("Three") was never called by passing an org.mockito.verification.VerificationMode to the verify() method. VerificationModes validate the number of times that a method is invoked, with whatever arguments are specified, and include the following:
times(n): specifies that you expect the method to be called n times.never(): specifies that you do not expect the method to be called.atLeastOnce(): specifies that you expect the method to be called at least once.atLeast(n): specifies that you expect the method to be called at least n times.atMost(n): specifies that you expect the method to be called at most n times.
Knowing this, we can verify that add("Three") is not called by executing the following:
verify(stringList, never()).add("Three")
It’s worth noting that when we do not specify a VerificationMode, it defaults to times(1), so the earlier calls were verifying that, for example, the add("One") was called once. Likewise, we verify that size() was invoked twice. Then, just to show how it works, we also verify that it was invoked at least once.
Now let’s test our service and repository from Listings 2 and 3 by spying on the repository and verifying the service calls the repository’s getStuff() method. This test is shown in Listing 6.
Listing 6. Testing a spied mock object (SpyAndMockTest.java)
package com.javaworld.geekcap.mockito;
import static org.junit.jupiter.api.Assertions.fail;
import static org.mockito.Mockito.spy;
import static org.mockito.Mockito.verify;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.List;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.Mockito;
import org.mockito.junit.jupiter.MockitoExtension;
@ExtendWith(MockitoExtension.class)
public class SpyAndMockTest {
// Create a Mock of a spied Repository
@Mock
Repository repository = spy(new Repository());
// Inject the respository into the service
@InjectMocks
Service service;
@Test
public void verifyRepositoryGetStuffIsCalled() {
try {
// Setup mock scenario
Mockito.when(repository.getStuff()).thenReturn(Arrays.asList("A", "B", "CDEFGHIJK", "12345", "1234"));
} catch (SQLException e) {
fail(e.getMessage());
}
// Execute the service that uses the mocked repository
List stuff = service.getStuffWithLengthLessThanFive();
// Validate the response
Assertions.assertNotNull(stuff);
Assertions.assertEquals(3, stuff.size());
try {
// Verify that the repository getStuff() method was called
verify(repository).getStuff();
} catch (SQLException e) {
fail(e.getMessage());
}
}
}
Most of the code in Listing 6 is the same as the test we wrote in Listing 4, but with two changes to support spying. First, when we want to spy on a mocked object, we cannot add both the @Mock and @Spy annotations to the object because Mockito only supports one of those annotations at a time. Instead, we can create a new repository, pass it to the org.mockito.Mockito.spy() method, and then annotate that with the @Mock annotation. The @Spy annotation is shorthand for invoking the spy() method, so the effect is the same. Now we have a mock object we can use to control the behavior, but Mockito will spy on all its method calls.
Next, we use the same verify() method we used to verify that add("One") was called to now verify the getStuff() method is called:
We need to wrap the method call in a try-catch block because the method signature defines that it can throw an SQLException, but since it doesn’t actually call the method, we would never expect the exception to be thrown.
You can extend this test with any of the VerificationMode variations I listed earlier. As a practical example, your service may maintain a cache of values and only query the repository when the requested value is not in the cache. If you mocked the repository and cache and then invoked a service method, Mockito assertions would allow you to validate that you got the correct response. With the proper cache values, you could infer that the service was getting the value from the cache, but you couldn’t know for sure. Spies, on the other hand, allow you to verify absolutely that the cache is checked and that the repository call is never made. So, combining mocks with spies allows you to more fully test your classes.
Mockito is a powerful tool, and we’ve only scratched the surface of what it can do. If you’ve ever wondered how you can test abhorrent conditions—such as network, database, timeout, or other I/O error conditions—Mockito is the tool for you. And, as you’ve seen here, it works elegantly with JUnit 5.
Conclusion
This article was a deeper exploration of JUnit 5’s unit testing capabilities, involving its integration with external tools. You saw how to integrate and use JUnit 5 with Hamcrest, a more advanced assertions framework, and Mockito, which you can use to mock and control a class’s dependencies. We also looked at Mockito’s spying capabilities, which you can use to not only test the return value of a method but also verify its behavior.
At this point, I hope you feel comfortable writing unit tests that not only test happy-path scenarios but also leverage tools like Mockito, which let you simulate edge cases and ensure your applications handle them correctly.
{kind=link}
Risk management in the public cloud is your job 4 Jul 2025, 5:00 am
I was excited to speak at a regional cloud computing summit hosted by one of the major cloud providers. My presentation focused on the many opportunities of public cloud and the essential need for risk management. Just before the event, I received an email stating that three of my slides, which discussed cloud outages and the risks of over-reliance on providers, had to be removed. Mentioning failures didn’t align with the host’s narrative of reliability.
Frustrated but not surprised, I removed the slides. During my presentation, I highlighted the importance of preparing for outages, disruptions, and other potential risks. I shared real-life incidents, such as major outages at top providers, that demonstrated how businesses unprepared for third-party failures can face significant financial, operational, and reputational damage. The audience’s response was mixed. Some nodded, clearly understanding the risks. Others, including event organizers at the back, appeared uneasy. Unsurprisingly, I haven’t been invited again.
Here’s the truth: Managing risk isn’t about doubting the effectiveness of cloud providers—it’s about ensuring resilience when the unexpected happens. If sharing that message makes people uncomfortable, I know I’m doing my job.
Reality does not care about your bias
Here’s another truth: Cloud outsourcing doesn’t eliminate risk; it simply shares it with the provider. The shared responsibility model of cloud governance clarifies certain aspects of risk management. A public cloud provider guarantees the reliability of their infrastructure, but the responsibility for the operating environment—applications, data, and workflows—still rests with the customer organization.
For example, providers will ensure their data centers meet uptime requirements and can withstand disasters at the physical or infrastructure level. However, they cannot control how a business organizes its data, enforces access policies, or mitigates the ripple effects of service provider outages on critical workflows. Businesses still bear the responsibility of maintaining continuity in the event of unexpected technical incidents.
Public cloud providers excel at scalability and innovation, but they aren’t immune to outages, latency issues, or cybersecurity risks. Organizations that fail to prepare for such possibilities become vulnerable to operational, financial, and reputational damage.
High-profile cloud incidents
Recent history provides clear examples of the risks associated with over-reliance on public cloud providers.
- AWS outage (December 2021): The reliability of one of the world’s largest cloud providers came into question during this outage. Many businesses, including cloud-dependent logistics firms and e-commerce platforms, experienced service disruptions that halted deliveries and hampered operations during the critical holiday season.
- Azure downtime (2022): A system failure in Microsoft Azure impacted SaaS applications and global enterprises alike, with financial services and regulated industries experiencing significant disruptions. These setbacks exposed the risks of relying heavily on a single provider.
- Google Cloud outage (2020): This incident disrupted major platforms such as Gmail and YouTube, as well as third-party applications operating on Google Cloud. Businesses without backup plans faced revenue losses.
Such incidents underscore the primary risks associated with relying on third-party cloud vendors. Despite their technological sophistication, the providers are not infallible, and their failures can have a direct impact on dependent businesses.
The ripple effect of third-party failures
When third-party providers face disruptions, the impact can be extensive. Public cloud providers are the foundation of many industries today, so any failure creates a ripple effect across organizations, markets, and consumers.
- Operational delays: Interruptions to essential services lead to productivity losses and, in some cases, operational paralysis. This is especially noticeable in industries such as healthcare or finance, where downtime can have serious real-world consequences for customers or lead to regulatory noncompliance.
- Financial losses: The cost of cloud-induced downtime can reach staggering levels. In highly regulated industries, losses can surpass millions of dollars per hour, considering missed business opportunities, regulatory fines, and remediation efforts.
- Regulatory and compliance risks: Certain industries are subject to stringent compliance standards. An outage caused by a third-party provider could prevent organizations from meeting these requirements, resulting in significant penalties and legal risks.
- Reputational damage: Customers and stakeholders often associate poor service with the business even if the issue lies with the cloud provider. Recovering from reputational loss is an expensive, extended process that can impact long-term business viability.
- Concentration risks: Relying too heavily on a single cloud service creates a single point of failure. If that provider goes down, operations in the dependent organization could come to a complete halt.
Risk management remains critical
Migrating systems to public cloud platforms does not exempt organizations from the need to build strong risk management frameworks. Viewing public cloud providers as strategic partners rather than infallible utilities helps businesses safeguard themselves against downstream risks.
- Thoroughly evaluate vendors: Look beyond their current service offerings to document their resiliency plans, security practices, and compliance certifications.
- Diversify cloud investments: Many organizations now adopt multicloud or hybrid solutions that combine services from multiple providers. This minimizes the risks of relying on a single provider and increases flexibility during incident recovery.
- Develop incident response plans for cloud disruption: Business continuity strategies should cover potential cloud outages, simulate disruptions, and establish clear action plans for rerouting workloads or restoring operations.
- Monitor cloud vendor dependencies: Consider active monitoring solutions to identify vulnerabilities or performance issues within your cloud ecosystem before they lead to outages.
- Engage in contractual risk protections: Contracts with public cloud providers should clearly define recovery expectations, contingency plans, and resolution timelines to ensure effective risk management. Auditing rights and regular performance evaluations must also be included in these agreements.
- Prioritize data and infrastructure backups: Data replicas and backup systems independent of your primary cloud service lower the risk of business stagnation during a disaster.
Outsourcing to the public cloud provides enterprises with opportunities to become more efficient and flexible; however, the inherent nature of cloud services requires careful oversight. The public cloud connects a business to global ecosystems where minor disruptions can lead to much larger problems. Effective use of cloud services doesn’t mean outsourcing responsibility. It involves taking proactive steps to reduce risks from the start. Only then can organizations fully realize the benefits of the public cloud, without compromising operational security or long-term success.
{kind=link}
Developing JavaScript apps with AI agents 4 Jul 2025, 5:00 am
There is a phenomenon in low-code and 4GL systems called the inner platform effect. Essentially, you take a tool and build an abstraction on top designed to make it simpler and end up creating a less powerful version of the same underlying system.
Artificial intelligence is producing something similar at the level of learning. We begin by using AI to control the underlying technology by telling it what we want. Then, we come to the gradual realization that we need to understand those underlying technologies and AI’s role in using them. We try to build an “inner platform” of understanding inside AI, only to discover that we must assume the work of learning ourselves, with AI as only part of that understanding.
With that in mind, this month’s report features the latest news and insights to fuel your JavaScript learning journey.
Top picks for JavaScript readers on InfoWorld
Putting agentic AI to work in Firebase Studio
Firebase Studio is among the best-in-class tools for AI-powered development, and it still has a few wrinkles to work out. Here’s a first look at building a full-stack JavaScript/TypeScript app with agentic AI.
Better together: Developing web apps with Astro and Alpine
Astro gives you next-generation server-side flexibility, and Alpine provides client-side reactivity in a tightly focused package. Put them together, and you get the best of both worlds.
10 JavaScript concepts you need to succeed with Node
Node is half of JavaScript’s universe. It’s also a major part of the enterprise infrastructure landscape. This article brings together some of the most important JavaScript concepts to understand when using Node, Bun, and Deno.
More good reads and JavaScript updates elsewhere
Vite reaches 7.0
As seen in the most recent State of JavaScript report, Vite is now a central component of JavaScript’s configuration ecosystem. An exciting sidebar in the latest release announcement is the connections to the VoidZero project and Rolldown, a Rust-based next-generation bundler that is part of the push to modernize Vite’s core. To check it out, just replace the default vite package with rolldown-vite.
What’s coming to JavaScript
This is a great overview from Deno of JavaScript proposals at all stages of development. One of the more exciting soon-to-be official updates is explicit resource management with using, which lets you declare a resource that will automatically be cleaned up when the block completes. Another is a new async version of Array.from, and much more.
Deno keeps up the fight over JavaScript trademark
You might not know that Deno is involved in a dispute with Oracle over Oracle’s use of the JavaScript trademark. This is an important area of IP that many JavaScript users will find interesting. In this blog post, Deno and Node creator Ryan Dahl asserts that JavaScript should not be a trademarked brand.
V8 deep dive on optimizations and Wasm
Here’s a great nerd-out on JavaScript engine internals and their relationship to WebAssembly. This piece is both a close look into the implementation of JavaScript in the real world and a bracing reminder of how much work and mind-power goes into the tools we use in our daily lives. I get the same feeling sometimes on a long road trip, when I suddenly realize: Hey, somebody built all this.
{kind=link}
AWS adds incremental and distributed training to Clean Rooms for scalable ML collaboration 3 Jul 2025, 7:59 am
AWS has rolled out new capabilities for its Clean Rooms service, designed to accelerate machine learning model development for enterprises while addressing data privacy concerns.
The updates, including incremental and distributed training, are designed to help enterprises, particularly in regulated industries, analyze shared datasets securely without copying or exposing sensitive information.
Analysts say the enhancements come amid rising demand for predictive analytics and personalized recommendations.
“The need for secure data collaboration is more critical than ever, with the need to protect sensitive information, yet share data with partners and other collaborators to improve machine learning models with collective data,” said Kathy Lange, research director at IDC.
“Often, enterprises cannot collect enough of their own data to cover a broad spectrum of outcomes, particularly in healthcare applications, disease outbreaks, or even in financial applications, like fraud or cybersecurity,” Lange added.
Incremental training to help with agility
The incremental training ability added to Clean Rooms will help enterprises build upon existing model artifacts, AWS said.
Model artifacts are the key outputs from the training process — such as files and data — that are required to deploy and operationalize a machine learning model in real-world applications.
The addition of incremental training “is a big deal,” according to Keith Townsend, founder of The Advisor Bench — a firm that provides consulting services for CIOs and CTOs.
“Incremental training allows models to be updated as new data becomes available — for example, as research partners contribute fresh datasets — without retraining from scratch,” Townsend said.
Seconding Townsend, Everest Group analyst Ishi Thakur said that the ability to update models with incremental data will bring agility to model development.
“Teams on AWS clean rooms will now be able to build on existing models, making it easier to adapt to shifting customer signals or operational patterns. This is particularly valuable in sectors like retail and finance where data flows continuously and speed matters,” Thakur said.
Typically, AWS Clean Rooms in the machine learning model context is used by enterprises for fraud detection, advertising, and marketing, said Bradley Shimmin, lead of the data and analytics practice at The Futurum Group.
“The service is focused on building lookalike models, which is a predictive ML model of the training data that can be used to find similar users in other datasets. So, something specific to advertising use cases or fraud detection,” Shimmin added.
Distributed training to help scale model development
The distributed training ability added to Clean Rooms will help enterprises scale model development, analysts said.
“This capability helps scale model development by breaking up complex training tasks across multiple compute nodes, which is a crucial advantage for enterprises grappling with high data volumes and compute-heavy use cases,” Thakur said.
Explaining how distributed training works, IDC’s Lange pointed out that AWS Clean Rooms ML — a feature inside the Clean Rooms service — uses Docker images that are SageMaker-compatible and stored in Amazon Elastic Container Registry (ECR).
“This allows users to leverage SageMaker’s distributed training capabilities, such as data parallelism and model parallelism, across multiple compute instances, enabling scalable, efficient training of custom ML models within AWS Clean Rooms,” Lange said, adding that other AWS components, such as AWS Glue — a serverless data integration service, are also involved.
Further, The Advisor Bench’s Townsend pointed out that AWS Clean Rooms’ distributed training feature will specifically help in use cases when one partner of the two-stakeholder enterprises doesn’t have deep expertise in distributed machine learning infrastructure.
Vendors such as Microsoft, Google, Snowflake, Databricks, and Salesforce also offer data clean rooms.
While Microsoft offers Azure Confidential Clean Room as a service designed to facilitate secure, multi-party data collaboration, Google offers BigQuery Clean Room — a tool that is built on BigQuery’s Analytics Hub and is focused on multi-party data analysis where data from a variety of contributors can be combined, with privacy protections in place, without the need to move or expose raw data.
Salesforce’s clean rooms feature is expected to be added to its Data Cloud by the end of the year, Shimmin said.
Demand for clean rooms expected to grow
The demand for clean rooms is expected to grow in the coming months.
“I expect we’ll see increased interest in and adoption of Clean Rooms as a service in the next 12-18 months,” said Shelly Kramer, founder and principal analyst at Kramer & Company, pointing out the deprecation of third-party cookies and increasingly challenging privacy regulations. “In data-driven industries, solutions for first-party data collaboration that can be done securely are in demand. That’s why we are seeing Clean Rooms as a service quickly becoming a standard. While today the early adopters are in some key sectors, the reality is that all enterprises today are, or should be, data-driven.”
On the other hand, IDC’s Lange pointed out that demand for clean rooms is growing specifically due to the rise in data volumes and data variety that are being stored and analyzed for patterns.
However, Kramer pointed out that enterprises may have challenges around the adoption of clean rooms.
“Integrating with existing workflows is a key challenge, as clean rooms don’t naturally fit within standard campaign planning and measurement processes. Therefore, embedding and operationalizing them effectively can require some effort,” Kramer said.
{kind=link}
Alibaba Cloud launches Eigen+ to cut costs and boost reliability for enterprise databases 3 Jul 2025, 7:33 am
Alibaba Cloud has developed a new cluster management system called Eigen+ that achieved a 36% improvement in memory allocation efficiency while eliminating Out of Memory (OOM) errors in production database environments, according to research presented at the recent SIGMOD conference.
The system addresses a fundamental challenge facing cloud providers: how to maximize memory utilization to reduce costs while avoiding catastrophic OOM errors that can crash critical applications and violate Service Level Objectives (SLOs).
The development, detailed in a research paper titled “Eigen+: Memory Over-Subscription for Alibaba Cloud Databases,” represents a significant departure from traditional memory over-subscription approaches used by major cloud providers, including AWS, Microsoft Azure, and Google Cloud Platform.
The system has been deployed in Alibaba Cloud’s production environment. The research paper claimed that in online MySQL clusters, Eigen+ “improves the memory allocation ratio of an online MySQL cluster by 36.21% (from 75.67% to 111.88%) on average, while maintaining SLO compliance with no OOM occurrences.”
For enterprise IT leaders, these numbers can translate into significant cost savings and improved reliability. The 36% improvement in memory allocation means organizations can run more database instances on the same hardware while actually reducing the risk of outages.
Alibaba Cloud’s Eigen+ has a classification-based memory management approach, whereas peers, AWS, Microsoft Azure, and Google Cloud, primarily rely on prediction-based memory management strategies, which, while effective, may not fully prevent OOM occurrences, explained Kaustubh K, practice director, Everest Group. “This difference in approach can position Alibaba Cloud’s Eigen+ with a greater technical differentiation in the cloud database market, potentially influencing future strategies of other hyperscalers.”
The technology is currently deployed across thousands of database instances in Alibaba Cloud’s production environment, supporting both online transaction processing (OLTP) workloads using MySQL and online analytical processing (OLAP) workloads using AnalyticDB for PostgreSQL, according to Alibaba researchers.
The memory over-subscription risk
Memory over-subscription — allocating more memory to virtual machines than physically exists — has become standard practice among cloud providers because VMs rarely use their full allocated memory simultaneously. However, this practice creates a dangerous balancing act for enterprises running mission-critical databases.
“Memory over-subscription enhances resource utilization by allowing more instances per machine, it increases the risk of Out of Memory (OOM) errors, potentially compromising service availability and violating Service Level Objectives (SLOs),” the researchers noted in their paper.
The stakes are particularly high for enterprise databases. “The figure clearly demonstrates that service availability declines significantly, often falling below the SLO threshold as the number of OOM events increases.”
Traditional approaches attempt to predict future memory usage based on historical data, then use complex algorithms to pack database instances onto servers. But these prediction-based methods often fail catastrophically when workloads spike unexpectedly.
“Eliminating Out of Memory (OOM) errors is critical for enterprise IT leaders, as such errors can lead to service disruptions and data loss,” Everest Group’s Kaustubh said. “While improvements in memory allocation efficiency are beneficial, ensuring system stability and reliability remains paramount. Enterprises should assess their cloud providers’ real-time monitoring capabilities, isolation mechanisms to prevent cross-tenant interference, and proactive mitigation techniques such as live migration and memory ballooning to handle overloads without service disruption. Additionally, clear visibility into oversubscription policies and strict adherence to Service Level Agreements (SLAs) are essential to maintain consistent performance and reliability.”
The Pareto Principle solution
Rather than trying to predict the unpredictable, Alibaba Cloud’s research team discovered that database OOM errors follow the Pareto Principle—also known as the 80/20 rule. “Database instances with memory utilization changes exceeding 5% within a week constitute no more than 5% of all instances, yet these instances lead to more than 90% of OOM errors,” the team said in the paper.
Instead of trying to forecast memory usage patterns, Eigen+ simply identifies which database instances are “transient” (prone to unpredictable memory spikes) and excludes them from over-subscription policies.
“By identifying transient instances, we can convert the complex problem of prediction into a more straightforward binary classification task,” the researchers said in the paper.
Eigen+ employs machine learning classifiers trained on both runtime metrics (memory utilization, queries per second, CPU usage) and operational metadata (instance specifications, customer tier, application types) to identify potentially problematic database instances.
The system uses a sophisticated approach that includes Markov chain state transition models to account for temporal dependencies in database behavior. “This allows it to achieve high accuracy in identifying transient instances that could cause OOM errors,” the paper added.
For steady instances deemed safe for over-subscription, the system employs multiple estimation methods, including percentile analysis, stochastic bin packing, and time series forecasting, depending on each instance’s specific usage patterns.
Quantitative SLO modeling
Perhaps most importantly for enterprise environments, Eigen+ includes a quantitative model for understanding how memory over-subscription affects service availability. Using quadratic logistic regression, the system can determine precise memory utilization thresholds that maintain target SLO compliance levels.
“Using the quadratic logistic regression model, we solve for the machine-level memory utilization (𝑋) corresponding to the desired 𝑃target,” the paper said.
This gives enterprise administrators concrete guidance on safe over-subscription levels rather than relying on guesswork or overly conservative estimates.
Recognizing that no classification system is perfect, Eigen+ includes reactive live migration capabilities as a fallback mechanism. When memory utilization approaches dangerous levels, the system automatically migrates database instances to less loaded servers.
During production testing, “Over the final two days, only five live migrations were initiated, including mirror databases. These tasks, which minimally impact operational systems, underscore the efficacy of Eigen+ in maintaining performance stability without diminishing user experience.”
Industry implications
The research suggests that cloud providers have been approaching memory over-subscription with unnecessarily complex prediction models when simpler classification approaches may be more effective. The paper stated that approaches used by Google Autopilot, AWS Aurora, and Microsoft Azure all rely on prediction-based methods that can fail under high utilization scenarios.
For enterprise IT teams evaluating cloud database services, Eigen+ represents a potential competitive advantage for Alibaba Cloud in markets where database reliability and efficient resource utilization are critical factors.
{kind=link}
Page processed in 0.262 seconds.
Powered by SimplePie 1.3.1, Build 20121030175403. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.